Hybrid Search with Qdrant’s FastEmbed
| Time: 20 min | Level: Beginner | Output: GitHub |
|---|
This tutorial shows you how to build and deploy your own hybrid search service to look through descriptions of companies from startups-list.com and pick the most similar ones to your query. The website contains the company names, descriptions, locations, and a picture for each entry.
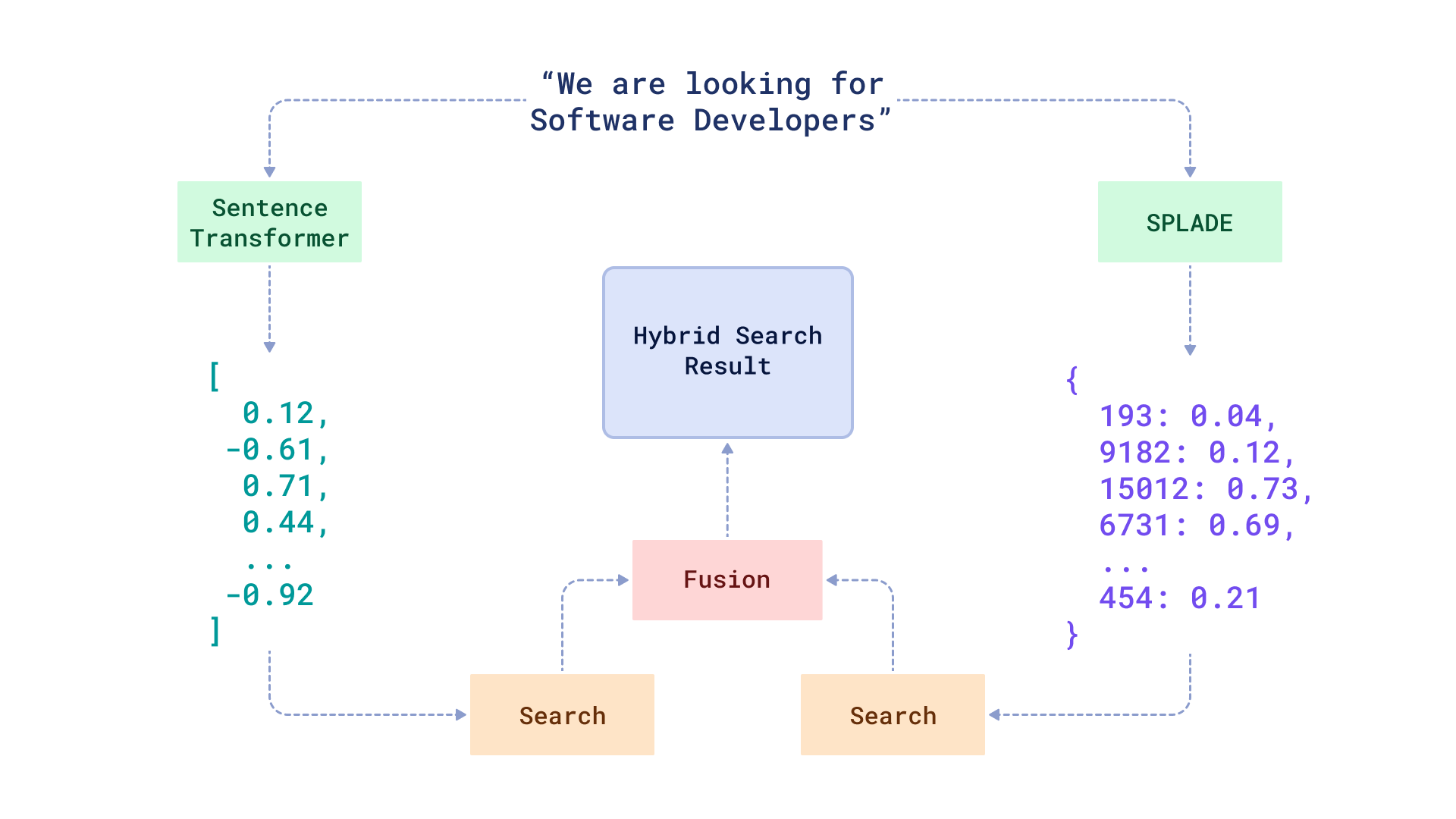
As we have already written on our blog, there is no single definition of hybrid search. In this tutorial we are covering the case with a combination of dense and sparse embeddings. The former ones refer to the embeddings generated by such well-known neural networks as BERT, while the latter ones are more related to a traditional full-text search approach.
Our hybrid search service will use Fastembed package to generate embeddings of text descriptions and FastAPI to serve the search API. Fastembed natively integrates with Qdrant client, so you can easily upload the data into Qdrant and perform search queries.
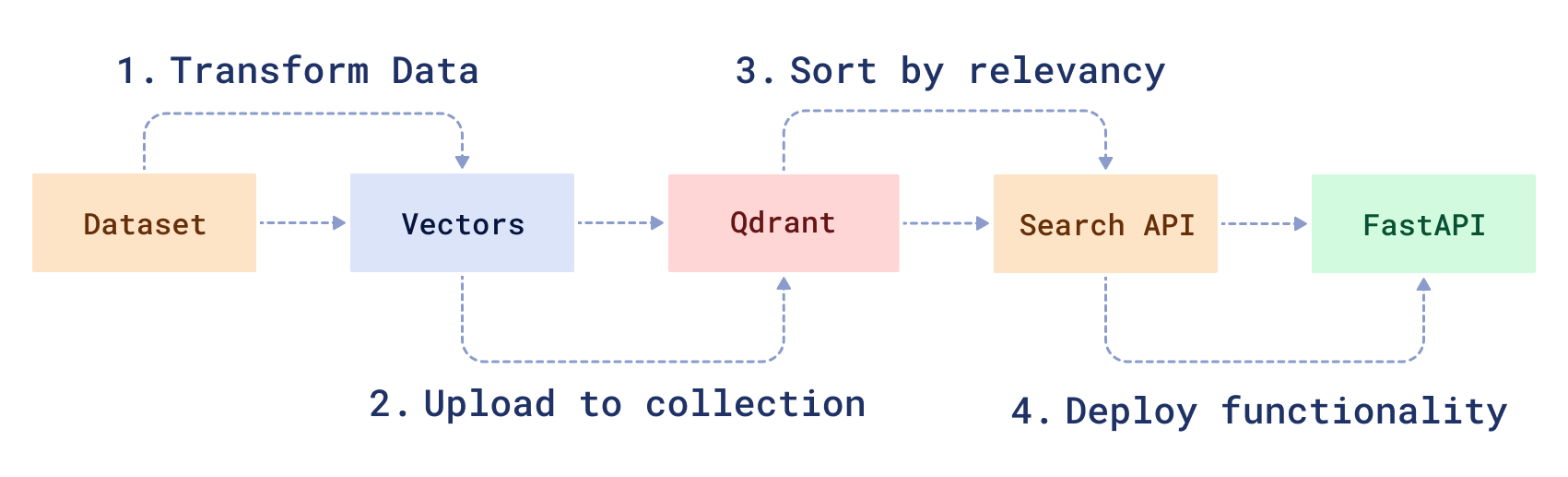
Workflow
To create a hybrid search service, you will need to transform your raw data and then create a search function to manipulate it. First, you will 1) download and prepare a sample dataset using a modified version of the BERT ML model. Then, you will 2) load the data into Qdrant, 3) create a hybrid search API and 4) serve it using FastAPI.
Prerequisites
To complete this tutorial, you will need:
- Docker - The easiest way to use Qdrant is to run a pre-built Docker image.
- Raw parsed data from startups-list.com.
- Python version >=3.9
Prepare sample dataset
To conduct a hybrid search on startup descriptions, you must first encode the description data into vectors. Fastembed integration into qdrant client combines encoding and uploading into a single step.
It also takes care of batching and parallelization, so you don’t have to worry about it.
Let’s start by downloading the data and installing the necessary packages.
- First you need to download the dataset.
wget https://storage.googleapis.com/generall-shared-data/startups_demo.json
Run Qdrant in Docker
Next, you need to manage all of your data using a vector engine. Qdrant lets you store, update or delete created vectors. Most importantly, it lets you search for the nearest vectors via a convenient API.
Note: Before you begin, create a project directory and a virtual python environment in it.
- Download the Qdrant image from DockerHub.
docker pull qdrant/qdrant
- Start Qdrant inside of Docker.
docker run -p 6333:6333 \
-v $(pwd)/qdrant_storage:/qdrant/storage \
qdrant/qdrant
You should see output like this
...
[2021-02-05T00:08:51Z INFO actix_server::builder] Starting 12 workers
[2021-02-05T00:08:51Z INFO actix_server::builder] Starting "actix-web-service-0.0.0.0:6333" service on 0.0.0.0:6333
Test the service by going to http://localhost:6333/. You should see the Qdrant version info in your browser.
All data uploaded to Qdrant is saved inside the ./qdrant_storage directory and will be persisted even if you recreate the container.
Upload data to Qdrant
- Install the official Python client to best interact with Qdrant.
pip install "qdrant-client[fastembed]>=1.14.2"
Note: This tutorial requires fastembed of version >=0.6.1.
At this point, you should have startup records in the startups_demo.json file and Qdrant running on a local machine.
Now you need to write a script to upload all startup data and vectors into the search engine.
- Create a client object for Qdrant.
# Import client library
from qdrant_client import QdrantClient, models
client = QdrantClient(url="http://localhost:6333")
- Choose models to encode your data and prepare collections.
In this tutorial, we will be using two pre-trained models to compute dense and sparse vectors correspondingly
The models are: sentence-transformers/all-MiniLM-L6-v2 and prithivida/Splade_PP_en_v1.
As soon as the choice is made, we need to configure a collection in Qdrant.
dense_vector_name = "dense"
sparse_vector_name = "sparse"
dense_model_name = "sentence-transformers/all-MiniLM-L6-v2"
sparse_model_name = "prithivida/Splade_PP_en_v1"
if not client.collection_exists("startups"):
client.create_collection(
collection_name="startups",
vectors_config={
dense_vector_name: models.VectorParams(
size=client.get_embedding_size(dense_model_name),
distance=models.Distance.COSINE
)
}, # size and distance are model dependent
sparse_vectors_config={sparse_vector_name: models.SparseVectorParams()},
)
Qdrant requires vectors to have their own names and configurations.
Parameters size and distance are mandatory, however, you can additionally specify extended configuration for your vectors, like quantization_config or hnsw_config.
- Read data from the file.
import json
payload_path = "startups_demo.json"
documents = []
metadata = []
with open(payload_path) as fd:
for line in fd:
obj = json.loads(line)
description = obj["description"]
dense_document = models.Document(text=description, model=dense_model_name)
sparse_document = models.Document(text=description, model=sparse_model_name)
documents.append(
{
dense_vector_name: dense_document,
sparse_vector_name: sparse_document,
}
)
metadata.append(obj)
In this block of code, we read data from startups_demo.json file and split it into two list: documents and metadata.
Documents are models with descriptions of startups and model names to embed data. Metadata is payload associated with each startup, such as the name, location, and picture.
We will use documents to encode the data into vectors.
- Encode and upload data.
client.upload_collection(
collection_name="startups",
vectors=tqdm.tqdm(documents),
payload=metadata,
parallel=4, # Use 4 CPU cores to encode data.
# This will spawn a model per process, which might be memory expensive
# Make sure that your system does not use swap, and reduce the amount
# # of processes if it does.
# Otherwise, it might significantly slow down the process.
# Requires wrapping code into if __name__ == '__main__' block
)
Upload processed data
Download and unpack the processed data from here or use the following script:
wget https://storage.googleapis.com/dataset-startup-search/startup-list-com/startups_hybrid_search_processed_40k.tar.gz
tar -xvf startups_hybrid_search_processed_40k.tar.gz
Then you can upload the data to Qdrant.
import json
import numpy as np
def named_vectors(
vectors: list[float],
sparse_vectors: list[models.SparseVector]
) -> dict:
for vector, sparse_vector in zip(vectors, sparse_vectors):
yield {
dense_vector_name: vector,
sparse_vector_name: models.SparseVector(**sparse_vector),
}
with open("dense_vectors.npy", "rb") as f:
vectors = np.load(f)
with open("sparse_vectors.json", "r") as f:
sparse_vectors = json.load(f)
with open("payload.json", "r") as f:
payload = json.load(f)
client.upload_collection(
"startups",
vectors=named_vectors(vectors, sparse_vectors),
payload=payload
)
The upload_collection method will encode all documents and upload them to Qdrant.
The parallel parameter enables data-parallelism instead of built-in ONNX parallelism.
Additionally, you can specify ids for each document, if you want to use them later to update or delete documents. If you don’t specify ids, they will be generated automatically.
You can monitor the progress of the encoding by passing tqdm progress bar to the upload_collection method.
from tqdm import tqdm
client.upload_collection(
collection_name="startups",
vectors=documents,
payload=metadata,
ids=tqdm(range(len(documents))),
)
Build the search API
Now that all the preparations are complete, let’s start building a neural search class.
In order to process incoming requests, the hybrid search class will need 3 things: 1) models to convert the query into a vector, 2) the Qdrant client to perform search queries, 3) fusion function to re-rank dense and sparse search results.
Qdrant supports 2 fusion functions for combining the results: reciprocal rank fusion and distribution based score fusion
- Create a file named
hybrid_searcher.pyand specify the following.
from qdrant_client import QdrantClient, models
class HybridSearcher:
DENSE_MODEL = "sentence-transformers/all-MiniLM-L6-v2"
SPARSE_MODEL = "prithivida/Splade_PP_en_v1"
def __init__(self, collection_name):
self.collection_name = collection_name
self.qdrant_client = QdrantClient()
- Write the search function.
def search(self, text: str):
search_result = self.qdrant_client.query_points(
collection_name=self.collection_name,
query=models.FusionQuery(
fusion=models.Fusion.RRF # we are using reciprocal rank fusion here
),
prefetch=[
models.Prefetch(
query=models.Document(text=text, model=self.DENSE_MODEL),
using=dense_vector_name,
),
models.Prefetch(
query=models.Document(text=text, model=self.SPARSE_MODEL),
using=sparse_vector_name,
),
],
query_filter=None, # If you don't want any filters for now
limit=5, # 5 the closest results
).points
# `search_result` contains models.QueryResponse structure
# We can access list of scored points with the corresponding similarity scores,
# vectors (if `with_vectors` was set to `True`), and payload via `points` attribute.
# Select and return metadata
metadata = [point.payload for point in search_result]
return metadata
- Add search filters.
With Qdrant it is also feasible to add some conditions to the search. For example, if you wanted to search for startups in a certain city, the search query could look like this:
...
city_of_interest = "Berlin"
# Define a filter for cities
city_filter = models.Filter(
must=[
models.FieldCondition(
key="city",
match=models.MatchValue(value=city_of_interest)
)
]
)
# NOTE: it is not a hybrid search! It's just a dense query for simplicity
search_result = self.qdrant_client.query_points(
collection_name=self.collection_name,
query=models.Document(text=text, model=self.DENSE_MODEL),
query_filter=city_filter,
limit=5
).points
...
You have now created a class for neural search queries. Now wrap it up into a service.
Deploy the search with FastAPI
To build the service you will use the FastAPI framework.
- Install FastAPI.
To install it, use the command
pip install fastapi uvicorn
- Implement the service.
Create a file named service.py and specify the following.
The service will have only one API endpoint and will look like this:
from fastapi import FastAPI
# The file where HybridSearcher is stored
from hybrid_searcher import HybridSearcher
app = FastAPI()
# Create a neural searcher instance
hybrid_searcher = HybridSearcher(collection_name="startups")
@app.get("/api/search")
def search_startup(q: str):
return {"result": hybrid_searcher.search(text=q)}
if __name__ == "__main__":
import uvicorn
uvicorn.run(app, host="0.0.0.0", port=8000)
- Run the service.
python service.py
- Open your browser at http://localhost:8000/docs.
You should be able to see a debug interface for your service.
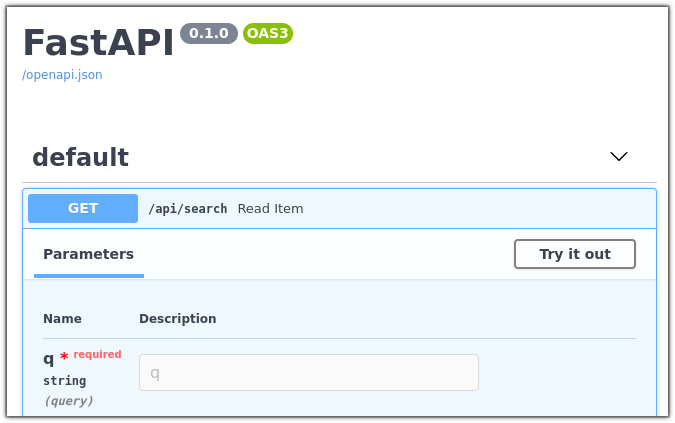
Feel free to play around with it, make queries regarding the companies in our corpus, and check out the results.
Join our Discord community, where we talk about vector search and similarity learning, publish other examples of neural networks and neural search applications.