































LegalTech Builder's Guide: Navigating Strategic Decisions with Vector Search
Daniel Azoulai
·June 10, 2025

On this page:
LegalTech Builder’s Guide: Navigating Strategic Decisions with Vector Search
LegalTech innovation needs a new search stack
LegalTech applications, more than most other application types, demand accuracy due to complex document structures, high regulatory stakes, and compliance requirements. Traditional keyword searches often fall short, failing to grasp semantic nuances essential for precise legal queries. Qdrant addresses these challenges by providing robust vector search solutions tailored for the complexities inherent in LegalTech applications.
Delivering precise results for high-stakes legal applications
Legal applications often operate in a high-stakes environment where false positives and imprecise matches can erode trust. Getting to the right result—fast—isn’t optional; it’s critical. Qdrant helps teams meet these demands through a set of tightly integrated techniques.
Filterable Hierarchical Navigable Small World (HNSW)
When your dataset contains millions (or billions) of legal vectors, every unnecessary comparison wastes time and compute. Pre-filtering cuts through the noise by narrowing the search space before retrieval even begins.
Filterable HNSW indexing improves speed, precision, and cost efficiency by applying filters before the search. It maintains speed advantages of vector search while allowing for precise filtering, addressing the inefficiencies that can occur when applying filters after the vector search. The Garden Intel case study exemplifies how its used in practice for a LegalTech use case.
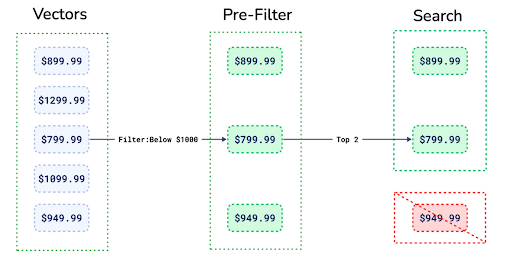
Figure: example of pre-filtering vectors (source)
Blend structured filters with semantic search for better case insights
Legal documents require a dual lens: exact matches for citations or statute references, and semantic understanding of legal reasoning. Hybrid search brings both into one query path. This is ideal for legal documents where exact citations and nuanced conceptual similarities coexist.
Minicoil, a sparse neural retriever, enriches lexical accuracy by understanding contextual token meanings. For instance, Aracor leverages hybrid search to precisely retrieve relevant clauses across extensive legal document repositories. Below is a pseudocode example:
POST /collections/{collection_name}/points/query
{
"prefetch": {
"query": [0.2, 0.8, ...],
"limit": 50
},
"query": {
"formula": {
"sum": [
"$score",
{
"mult": [
0.5,
{
"key": "tag",
"match": { "any": ["h1", "h2", "h3", "h4"] }
}
]
},
{
"mult": [
0.25,
{
"key": "tag",
"match": { "any": ["p", "li"] }
}
]
}
]
}
}
}
Leveraging Late-Interaction Models for Rich Documents
Traditional OCR pipelines can add complexity and create accuracy challenges. But late-interaction models simplify the ingestion pipeline by running at the reranking stage.
Models like (ColPali and ColQwen) bypass traditional OCR pipelines, directly processing images of complex documents. They enhance accuracy by maintaining original layouts and contextual integrity, simplifying your retrieval pipelines. The tradeoff is a heavier application, but these challenges can be addressed with further optimization.
Enabling highly granular accuracy for complex legal searches
Legal relevance is critical down to the token level. Distinguishing between, for example, “shall” and “may”, becomes important.
Utilize ColBERT for high-accuracy reranking, allowing highly granular, token-level similarity estimation with high accuracy results. It is also faster than traditional cross-encoders for reranking. Since Qdrant supports multivectors natively, this is easy to integrate into your search application.
# Step 1: Retrieve hybrid results using dense and sparse queries
hybrid_results = client.search(
collection_name="legal-hybrid-search",
query_vector=dense_vector,
query_sparse_vector=sparse_vector,
limit=20,
with_payload=True
)
# Step 2: Tokenize the query using ColBERT
colbert_query_tokens = colbert_model.query_tokenize(query_text)
# Step 3: Score and rerank results using ColBERT token-level scoring
reranked = sorted(
hybrid_results,
key=lambda doc: colbert_model.score(
colbert_query_tokens,
colbert_model.doc_tokenize(doc["payload"]["document"])
),
reverse=True
)
# Step 4: Return top-k reranked results
final_results = reranked[:5]
Prioritize the legal logic that matters most in search rankings
Not every clause is created equal. Legal professionals often care more about specific provisions, jurisdictions, or case types, for example.
Qdrant’s Score Boosting Reranker lets you integrate domain-specific logic (e.g., jurisdiction or recent cases) directly into search rankings, ensuring results align precisely with legal business rules.
POST /collections/legal-docs/points/query
{
"prefetch": {
"query": [0.21, 0.77, ...],
"limit": 50
},
"query": {
"formula": {
"sum": [
"$score", // dense semantic match
{
"mult": [0.6, { "key": "section", "match": { "any": ["Clause", "Provision", "Section"] } }]
},
{
"mult": [0.3, { "key": "heading", "match": { "any": ["Definitions", "Governing Law", "Termination"] } }]
},
{
"mult": [0.1, { "key": "paragraph_type", "match": { "any": ["Interpretation", "Remedy"] } }]
}
]
}
}
}
Ensuring Scalability and High Performance
Even the most accurate system can fail if it can’t handle load or stay cost-effective. Once your LegalTech product reaches significant usage, indexing speed and operational efficiency start to matter just as much as relevance. Qdrant’s capabilities can also address the challenges.
Efficient Indexing and Retrieval Techniques
Legal datasets are growing, and so are the compute bills. From GPU acceleration to quantization, Qdrant gives teams the tools to scale without spiraling costs.
GPU indexing accelerates indexing by up to 10x compared to CPU methods, offering vendor-agnostic compatibility with modern GPUs via Vulkan API.
Vector quantization compresses embeddings, significantly reducing memory and operational costs. It results in lower accuracy, so carefully consider this option. For example, LawMe, a Qdrant user, uses Binary Quantization to cost-effectively add more data for its AI Legal Assistants.
Getting Started: Choosing Your Search Infrastructure
Deploy in private, cloud, or hybrid environments without sacrificing control
No matter your stage—prototype or production—your stack will have to meet both engineering and compliance needs. Qdrant supports flexible deployment strategies, including managed cloud and hybrid cloud, along with open-source solutions via Docker, enabling easy scaling and secure management of legal data.
Build and iterate quickly with responsive support and built-in tooling
Complex Legal AI applications may need extra support. Qdrant’s open-source commitment, FastEmbed integration, and responsive team help unblock your path to value.
We’re very responsive on our Qdrant Discord channel, have a free Qdrant Cloud tier, are committed to open-source, and have great documentation. Also, check out embedding workflows via our FastEmbed integration to simplify the inference process.
Exploratory & Interactive Development
Legal search often requires iteration—tweaking prompts, reranking weights, or understanding why a clause ranked low. Qdrant’s Web UI makes these loops visible and actionable through interactive experimentation, HTTP-based calls, visual debugging, and semantic similarity visualizations.
Enterprise-Grade Capabilities
From law firms to global SaaS providers, enterprise LegalTech builders need auditability, control, and compliance. Qdrant comes equipped with the features that keep security teams happy.
Qdrant’s enterprise-ready features, including RBAC (including on Cloud), SSO, Database API Keys (down to the vector level), comprehensive monitoring, and observability, ensure secure, compliant, and manageable deployments at scale.
Qdrant is also SOC II Type II and HIPAA compliant (link).
Build legal AI that balances accuracy, compliance, and cost at scale
The challenge isn’t just building something that works—it’s building something that works at scale, under legal scrutiny, and with economic efficiency. Qdrant gives LegalTech teams that edge.
Successfully navigating LegalTech challenges requires careful balance across accuracy, compliance, scalability, and cost. Qdrant provides a comprehensive, flexible, and powerful vector search stack, empowering LegalTech to build robust and reliable AI applications.
Ready to build? Start exploring Qdrant’s capabilities today through Qdrant Cloud to strategically manage and advance your legal-tech applications.
