Automate Qdrant Workflows with n8n
| Time: 45 min | Level: Intermediate |
|---|
This tutorial shows how to combine Qdrant with n8n low-code automation platform to cover use cases beyond basic Retrieval-Augmented Generation (RAG). You’ll learn how to use vector search for recommendations and unstructured big data analysis.
Setting Up Qdrant in n8n
To start using Qdrant with n8n, you need to provide your Qdrant instance credentials in the credentials tab. Select QdrantApi from the list.
Qdrant Cloud
To connect Qdrant Cloud to n8n:
- Open the Cloud Dashboard and select a cluster.
- From the Cluster Details, copy the
Endpointaddress—this will be used as theQdrant URLin n8n. - Navigate to the API Keys tab and copy your API key—this will be the
API Keyin n8n.
For a walkthrough, see this step-by-step video guide.
Local Mode
For a fully local experimnets-driven setup, a valuable option is n8n’s Self-hosted AI Starter Kit. This is an open-source Docker Compose template for local AI & low-code development environment.
This kit includes a local instance of Qdrant. To get started:
- Follow the instructions in the repository to install the AI Starter Kit.
- Use the values from the
docker-compose.ymlfile to fill in the connection details.
The default Qdrant configuration in AI Starter Kit’s docker-compose.yml looks like this:
qdrant:
image: qdrant/qdrant
hostname: qdrant
container_name: qdrant
networks: ['demo']
restart: unless-stopped
ports:
- 6333:6333
volumes:
- qdrant_storage:/qdrant/storage
From this configuration, the Qdrant URL in n8n Qdrant credentials is http://qdrant:6333/.
To set up a local Qdrant API key, add the following lines to the YAML file:
qdrant:
...
volumes:
- qdrant_storage:/qdrant/storage
environment:
- QDRANT_API_KEY=test
After saving the configuration and running the Starter Kit, use QDRANT_API_KEY value (e.g., test) as the API Key and http://qdrant:6333/ as the Qdrant URL.
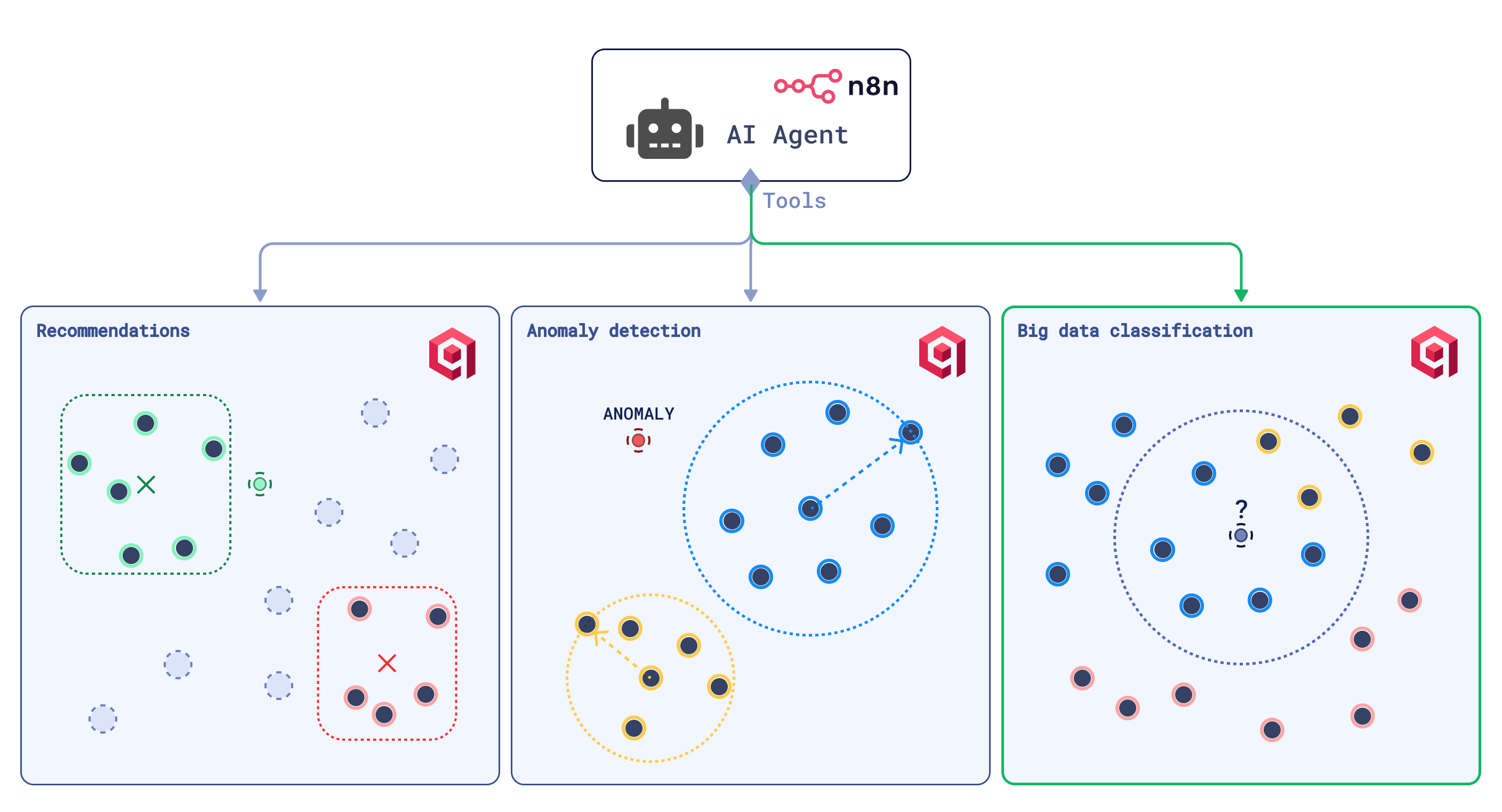
Qdrant + n8n Beyond Simple Similarity Search
Vector search’s ability to determine semantic similarity between objects is often used to address models’ hallucinations, powering the memory of Retrieval-Augmented Generation-based applications. Yet there’s more to vector search than just a “knowledge base” role.
The combination of similarity and dissimilarity metrics in vector space expands vector search to recommendations, discovery search, and large-scale unstructured data analysis.
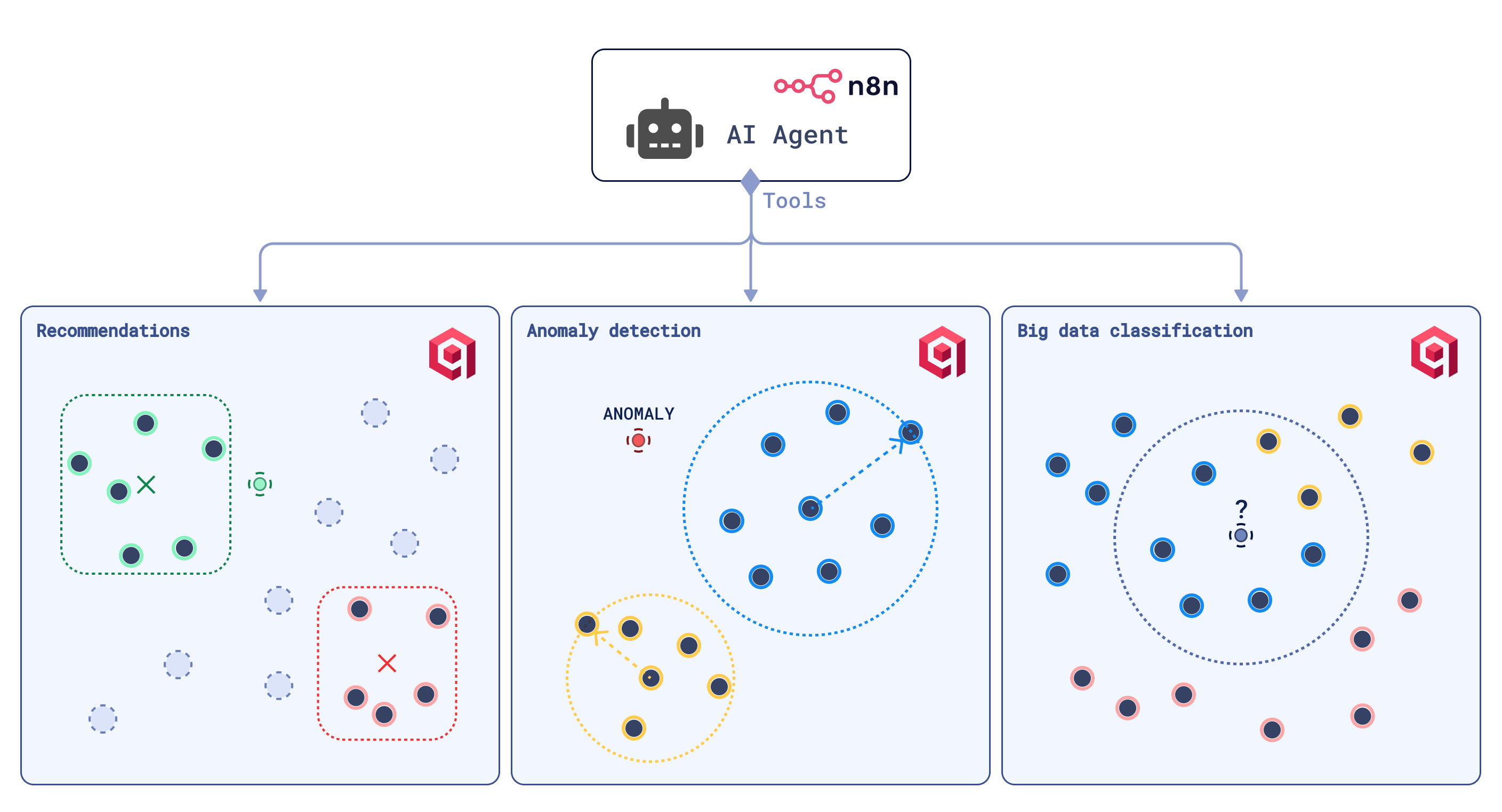
Recommendations
When searching for new music, films, books, or food, it can be difficult to articulate exactly what we want. Instead, we often rely on discovering new content through comparison to examples of what we like or dislike.
The Qdrant Recommendation API is built to make these discovery searches possible by using positive and negative examples as anchors. It helps find new relevant results based on your preferences.
Movie Recommendations
Imagine a home cinema night—you’ve already watched Harry Potter 666 times and crave a new series featuring young wizards. Your favorite streaming service repetitively recommends all seven parts of the millennial saga. Frustrated, you turn to n8n to create an Agentic Movie Recommendation tool.
Setup:
- Dataset: We use movie descriptions from the IMDB Top 1000 Kaggle dataset.
- Embedding Model: We’ll use OpenAI
text-embedding-3-small, but you can opt for any other suitable embedding model.
Workflow:
A Template Agentic Movie Recommendation Workflow consists of three parts:
- Movie Data Uploader: Embeds movie descriptions and uploads them to Qdrant using the Qdrant Vector Store Node (now this can also be done using the official Qdrant Node for n8n). In the template workflow, the dataset is fetched from GitHub, but you can use any supported storage, for example Google Cloud Storage node.
- AI Agent: Uses the AI Agent Node to formulate Recommendation API calls based on your natural language requests. Choose an LLM as a “brain” and define a JSON schema for the recommendations tool powered by Qdrant. This schema lets the LLM map your requests to the tool input format.
- Recommendations Tool: A subworkflow that calls the Qdrant Recommendation API using the HTTP Request Node (now this can also be done using the official Qdrant Node for n8n). The agent extracts relevant and irrelevant movie descriptions from your chat message and passes them to the tool. The tool embeds them with
text-embedding-3-smalland uses the Qdrant Recommendation API to get movie recommendations, which are passed back to the agent.
Set it up, run a chat and ask for “something about wizards but not Harry Potter.” What results do you get?
If you’d like a detailed walkthrough of building this workflow step-by-step, watch the video below:
This recommendation scenario is easily adaptable to any language or data type (images, audio, video).
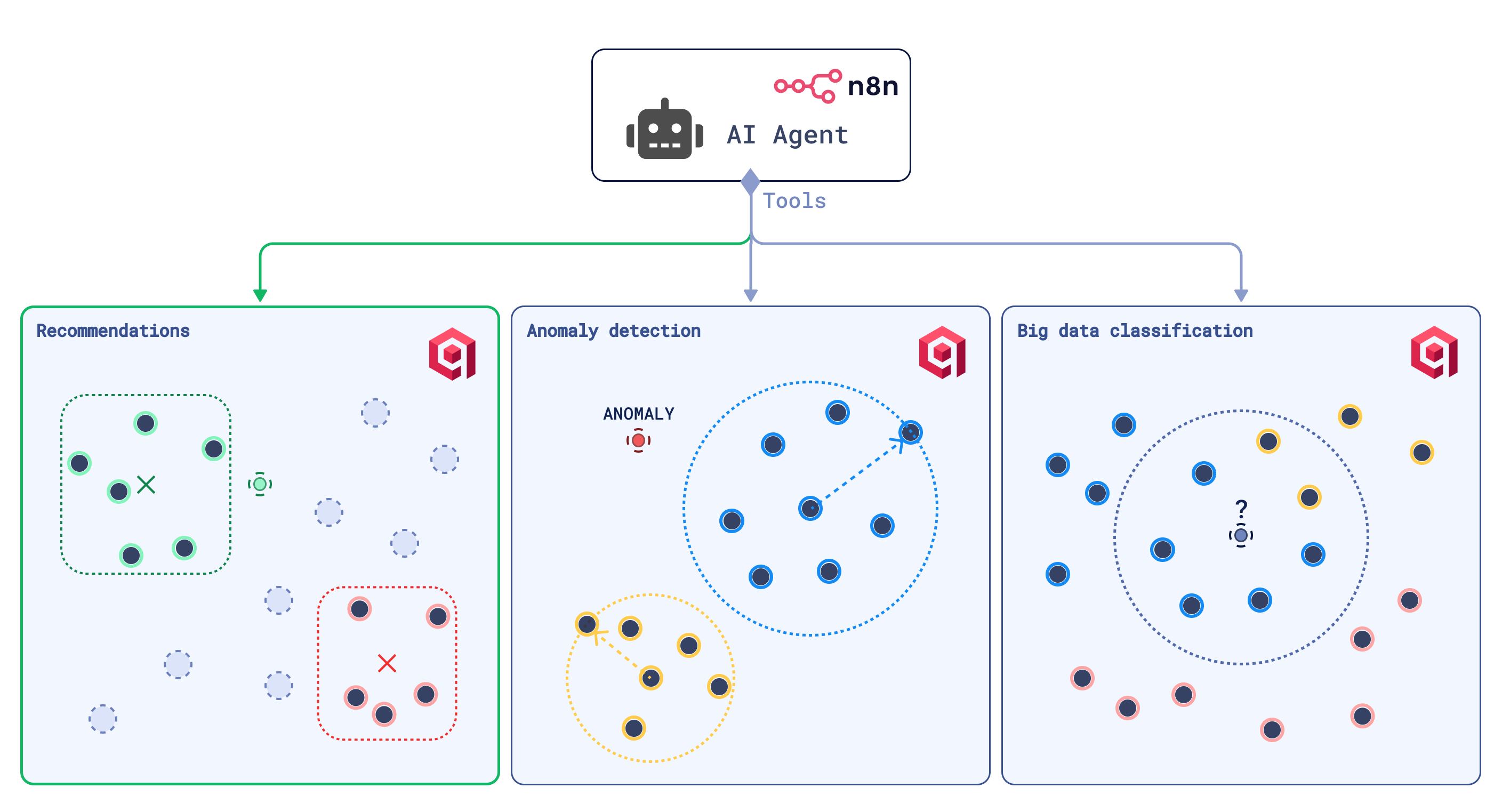
Big Data Analysis
The ability to map data to a vector space that reflects items’ similarity and dissimilarity relationships provides a range of mathematical tools for data analysis.
Vector search dedicated solutions are built to handle billions of data points and quickly compute distances between them, simplifying clustering, classification, dissimilarity sampling, deduplication, interpolation, and anomaly detection at scale.
The combination of this vector search feature with automation tools like n8n creates production-level solutions capable of monitoring data temporal shifts, managing data drift, and discovering patterns in seemingly unstructured data.
A practical example is worth a thousand words. Let’s look at Qdrant-based anomaly detection and classification tools, which are designed to be used by the n8n AI Agent node for data analysis automation.
To make it more interesting, this time we’ll focus on image data.
Anomaly Detection Tool
One definition of “anomaly” comes intuitively after projecting vector representations of data points into a 2D space—Qdrant webUI provides this functionality.
Points that don’t belong to any clusters are more likely to be anomalous.
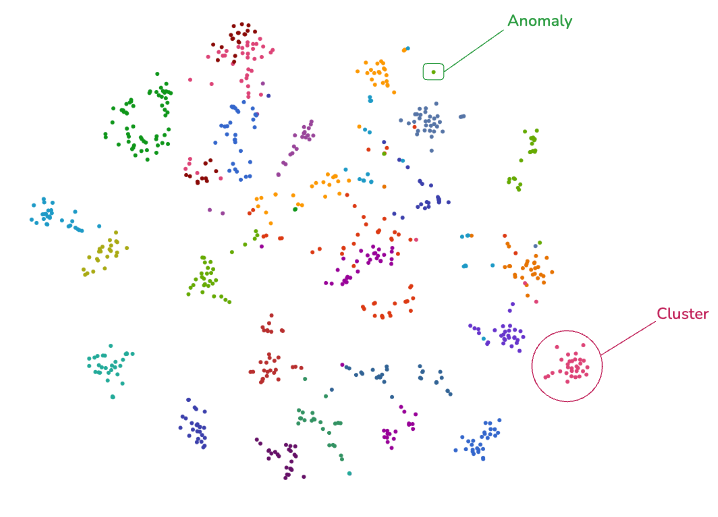
With that intuition comes the recipe for building an anomaly detection tool. We will demonstrate it on anomaly detection in agricultural crops. Qdrant will be used to:
- Store vectorized images.
- Identify a “center” (representative) for each crop cluster.
- Define the borders of each cluster.
- Check if new images fall within these boundaries. If an image does not fit within any cluster, it is flagged as anomalous. Alternatively, you can check if an image is anomalous to a specific cluster.
Setup:
- Dataset: We use the Agricultural Crops Image Classification dataset.
- Embedding Model: The Voyage AI multimodal embedding model. It can project images and text data into a shared vector space.
1. Uploading Images to Qdrant
Since the Qdrant Vector Store node does not support embedding models outside the predefined list (which doesn’t include Voyage AI), we embed and upload data to Qdrant via direct API calls in HTTP Request nodes.
With the release of the official Qdrant node, which supports arbitrary vectorized input, the HTTP Request node can now be replaced with this native integration.
Workflow:
There are three workflows: (1) Uploading images to Qdrant (2) Setting up cluster centers and thresholds (3) Anomaly detection tool itself.
An 1/3 Uploading Images to Qdrant Template Workflow consists of the following blocks:
- Check Collection: Verifies if a collection with the specified name exists in Qdrant. If not, it creates one.
- Payload Index: Adds a payload index on the
crop_namepayload (metadata) field. This field stores crop class labels, and indexing it improves the speed of filterable searches in Qdrant. It changes the way a vector index is constructed, adapting it for fast vector search under filtering constraints. For more details, refer to this guide on filtering in Qdrant. - Fetch Images: Fetches images from Google Cloud Storage using the Google Cloud Storage node.
- Generate IDs: Assigns UUIDs to each data point.
- Embed Images: Embeds the images using the Voyage API.
- Batch Upload: Uploads the embeddings to Qdrant in batches.
2. Defining a Cluster Representative
We used two approaches (it’s not an exhaustive list) to defining a cluster representative, depending on the availability of labeled data:
| Method | Description |
|---|---|
| Medoids | A point within the cluster that has the smallest total distance to all other cluster points. This approach needs labeled data for each cluster. |
| Perfect Representative | A representative defined by a textual description of the ideal cluster member—the multimodality of Voyage AI embeddings allows for this trick. For example, for cherries: “Small, glossy red fruits on a medium-sized tree with slender branches and serrated leaves.” The closest image to this description in the vector space is selected as the representative. This method requires experimentation to align descriptions with real data. |
Workflow:
Both methods are demonstrated in the 2/3 Template Workflow for Anomaly Detection.
| Method | Steps |
|---|---|
| Medoids | 1. Sample labeled cluster points from Qdrant. 2. Compute a pairwise distance matrix for the cluster using Qdrant’s Distance Matrix API. This API helps with scalable cluster analysis and data points relationship exploration. Learn more in this article. 3. For each point, calculate the sum of its distances to all other points. The point with the smallest total distance (or highest similarity for COSINE distance metric) is the medoid. 4. Mark this point as the cluster representative. |
| Perfect Representative | 1. Define textual descriptions for each cluster (e.g., AI-generated). 2. Embed these descriptions using Voyage. 3. Find the image embedding closest to the description one. 4. Mark this image as the cluster representative. |
3. Defining the Cluster Border
Workflow:
The approach demonstrated in 2/3 Template Workflow for Anomaly Detection works similarly for both types of cluster representatives.
- Within a cluster, identify the furthest data point from the cluster representative (it can also be the 2nd or Xth furthest point; the best way to define it is through experimentation—for us, the 5th furthest point worked well). Since we use COSINE similarity, this is equivalent to the most similar point to the opposite of the cluster representative (its vector multiplied by -1).
- Save the distance between the representative and respective furthest point as the cluster border (threshold).
4. Anomaly Detection Tool
Workflow:
With the preparatory steps complete, you can set up the anomaly detection tool, demonstrated in the 3/3 Template Workflow for Anomaly Detection.
Steps:
- Choose the method of the cluster representative definition.
- Fetch all the clusters to compare the candidate image against.
- Using Voyage AI, embed the candidate image in the same vector space.
- Calculate the candidate’s similarity to each cluster representative. The image is flagged as anomalous if the similarity is below the threshold for all clusters (outside the cluster borders). Alternatively, you can check if it’s anomalous to a particular cluster, for example, the cherries one.
Anomaly detection in image data has diverse applications, including:
- Moderation of advertisements.
- Anomaly detection in vertical farming.
- Quality control in the food industry, such as detecting anomalies in coffee beans.
- Identifying anomalies in map tiles for tasks like automated map updates or ecological monitoring.
This tool is easily adaptable to these use cases.
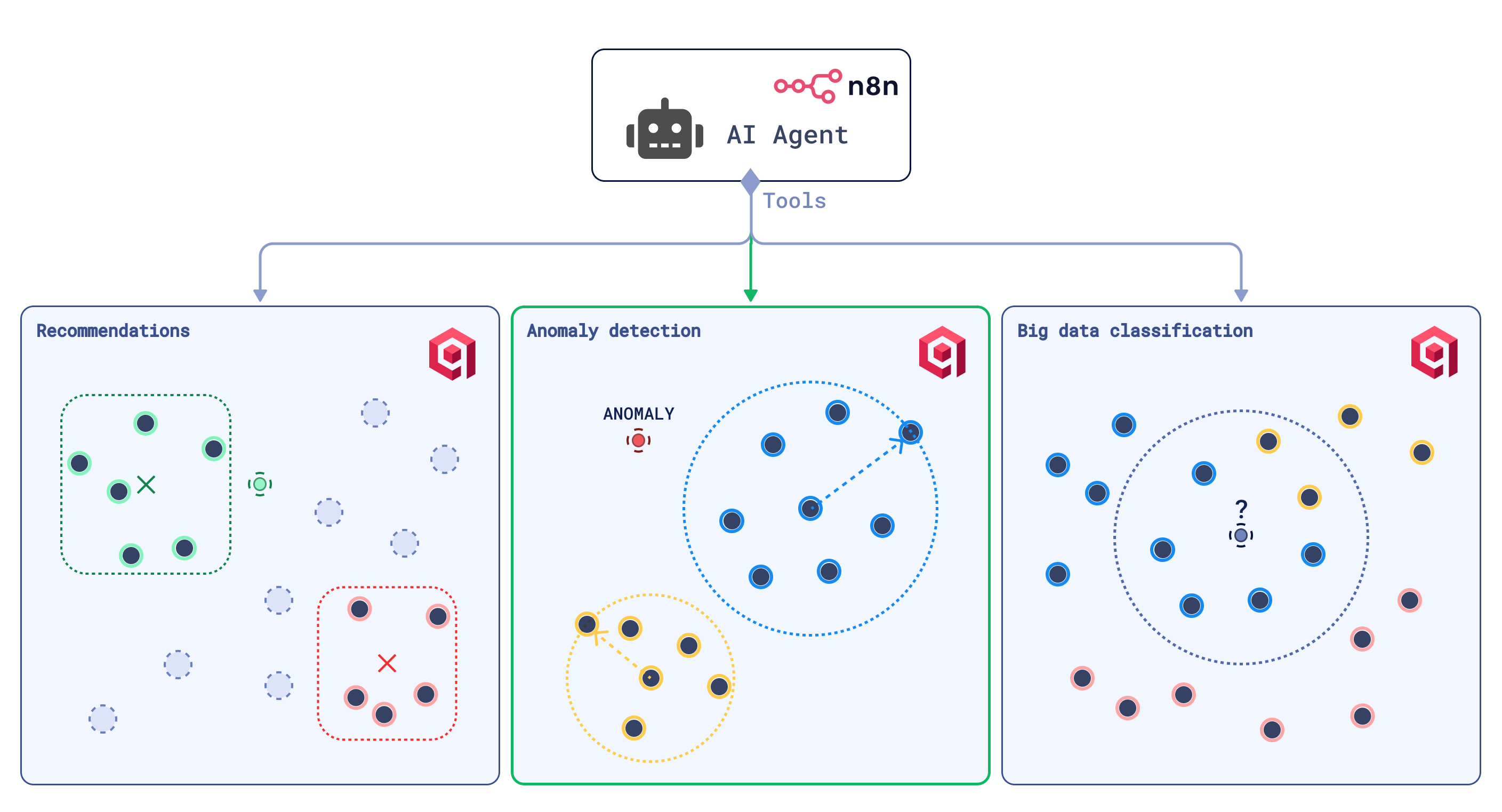
Classification Tool
The anomaly detection tool can also be used for classification, but there’s a simpler approach: K-Nearest Neighbors (KNN) classification.
“Show me your friends, and I will tell you who you are.”
The KNN method labels a data point by analyzing its classified neighbors and assigning this point the majority class in the neighborhood. This approach doesn’t require all data points to be labeled—a subset of labeled examples can serve as anchors to propagate labels across the dataset.
Let’s build a KNN-based image classification tool.
Setup
- Dataset: We’ll use the Land-Use Scene Classification dataset. Satellite imagery analysis has applications in ecology, rescue operations, and map updates.
- Embedding Model: As for anomaly detection, we’ll use the Voyage AI multimodal embedding model.
Additionally, it’s good to have test and validation data to determine the optimal value of K for your dataset.
Workflow:
Uploading images to Qdrant can be done using the same workflow—1/3 Uploading Images to Qdrant Template Workflow, just by swapping the dataset.
The KNN-Classification Tool Template has the following steps:
- Embed Image: Embeds the candidate for classification using Voyage.
- Fetch neighbors: Retrieves the K closest labeled neighbors from Qdrant.
- Majority Voting: Determines the prevailing class in the neighborhood by simple majority voting.
- Optional: Ties Resolving: In case of ties, expands the neighborhood radius.
Of course, this is a simple solution, and there exist more advanced approaches with higher precision & no need for labeled data—for example, you could try metric learning with Qdrant.
Though classification seems like a task that was solved in machine learning decades ago, it’s not so trivial to deal with in production. Issues like data drift, shifting class definitions, mislabeled data, and fuzzy differences between classes create unexpected problems, which require continuous adjustments of classifiers, and vector search can be an unusual but effective solution, due to its scalability.
Live Walkthrough
To see how n8n agents use these tools in practice, and to revisit the main ideas of the “Big Data Analysis” section, watch our integration webinar:
Conclusion
Vector search is not limited to similarity search or basic RAG. When combined with automation platforms like n8n, it becomes a powerful tool for building smarter systems. Think dynamic routing in customer support, content moderation based on user behavior, or AI-driven alerts in data monitoring dashboards.
This tutorial showed how to use Qdrant and n8n for AI-backed recommendations, classification, and anomaly detection. But that’s just the start—try vector search for:
- Deduplication
- Dissimilarity search
- Diverse sampling
With Qdrant and n8n, there’s plenty of room to create something unique!