Agentic RAG with LangGraph and Qdrant
| Time: 45 min | Level: Intermediate |
|---|
Traditional Retrieval-Augmented Generation (RAG) systems follow a straightforward path: query → retrieve → generate. Sure, this works well for many scenarios. But let’s face it—this linear approach often struggles when you’re dealing with complex queries that demand multiple steps or pulling together diverse types of information.
Agentic RAG takes things up a notch by introducing AI agents that can orchestrate multiple retrieval steps and smartly decide how to gather and use the information you need. Think of it this way: in an Agentic RAG workflow, RAG becomes just one powerful tool in a much bigger and more versatile toolkit.
By combining LangGraph’s robust state management with Qdrant’s cutting-edge vector search, we’ll build a system that doesn’t just answer questions—it tackles complex, multi-step information retrieval tasks with finesse.
What We’ll Build
We’re building an AI agent to answer questions about Hugging Face and Transformers documentation using LangGraph. At the heart of our AI agent lies LangGraph, which acts like a conductor in an orchestra. It directs the flow between various components—deciding when to retrieve information, when to perform a web search, and when to generate responses.
The components are: two Qdrant vector stores and the Brave web search engine. However, our agent doesn’t just blindly follow one path. Instead, it evaluates each query and decides whether to tap into the first vector store, the second one, or search the web.
This selective approach gives your system the flexibility to choose the best data source for the job, rather than being locked into the same retrieval process every time, like traditional RAG. While we won’t dive into query refinement in this tutorial, the concepts you’ll learn here are a solid foundation for adding that functionality down the line.
Workflow
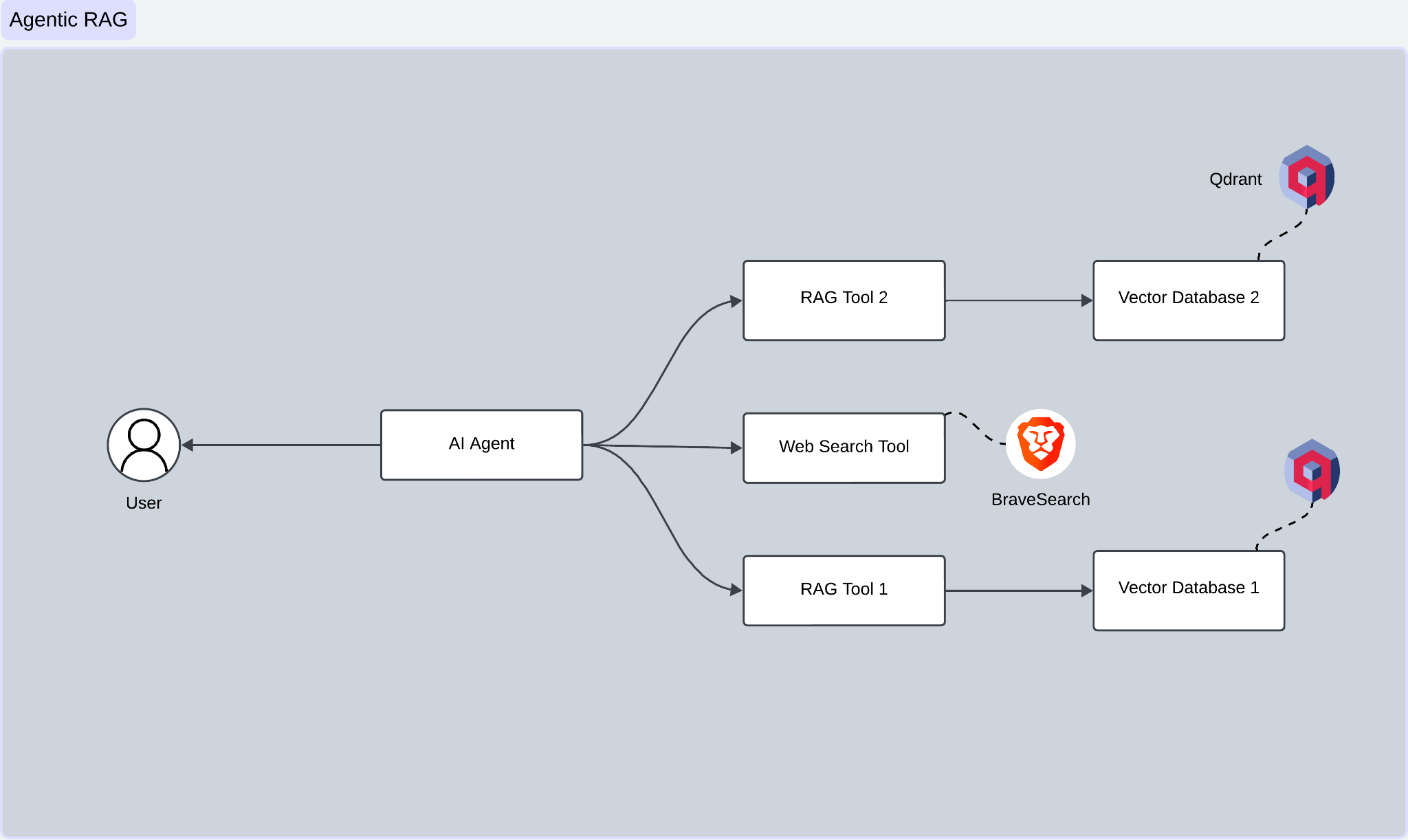
| Step | Description |
|---|---|
| 1. User Input | You start by entering a query or request through an interface, like a chatbot or a web form. This query is sent straight to the AI Agent, the brain of the operation. |
| 2. AI Agent Processes the Query | The AI Agent analyzes your query, figuring out what you’re asking and which tools or data sources will best answer your question. |
| 3. Tool Selection | Based on its analysis, the AI Agent picks the right tool for the job. Your data is spread across two vector databases, and depending on the query, it chooses the appropriate one. For queries needing real-time or external web data, the agent taps into a web search tool powered by BraveSearchAPI. |
| 4. Query Execution | The AI Agent then puts its chosen tool to work: - RAG Tool 1 queries Vector Database 1. - RAG Tool 2 queries Vector Database 2. - Web Search Tool dives into the internet using the search API. |
| 5. Data Retrieval | The results roll in: - Vector Database 1 and 2 return the most relevant documents for your query. - The Web Search Tool provides up-to-date or external information. |
| 6. Response Generation | Using a text generation model (like GPT), the AI Agent crafts a detailed and accurate response tailored to your query. |
| 7. User Response | The polished response is sent back to you through the interface, ready to use. |
The Stack
The architecture taps into cutting-edge tools to power efficient Agentic RAG workflows. Here’s a quick overview of its components and the technologies you’ll need:
- AI Agent: The mastermind of the system, this agent parses your queries, picks the right tools, and integrates the responses. We’ll use OpenAI’s gpt-4o as the reasoning engine, managed seamlessly by LangGraph.
- Embedding: Queries are transformed into vector embeddings using OpenAI’s text-embedding-3-small model.
- Vector Database: Embeddings are stored and used for similarity searches, with Qdrant stepping in as our database of choice.
- LLM: Responses are generated using OpenAI’s gpt-4o, ensuring answers are accurate and contextually grounded.
- Search Tools: To extend RAG’s capabilities, we’ve added a web search component powered by BraveSearchAPI, perfect for real-time and external data retrieval.
- Workflow Management: The entire orchestration and decision-making flow is built with LangGraph, providing the flexibility and intelligence needed to handle complex workflows.
Ready to start building this system from the ground up? Let’s get to it!
Implementation
Before we dive into building our agent, let’s get everything set up.
Imports
Here’s a list of key imports required:
import os
import json
from typing import Annotated, TypedDict
from dotenv import load_dotenv
from langchain.embeddings import OpenAIEmbeddings
from langgraph import StateGraph, tool, ToolNode, ToolMessage
from langchain.document_loaders import HuggingFaceDatasetLoader
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain.llms import ChatOpenAI
from qdrant_client import QdrantClient
from qdrant_client.http.models import VectorParams
from brave_search import BraveSearch
Qdrant Vector Database Setup
We’ll use Qdrant Cloud as our vector store for document embeddings. Here’s how to set it up:
| Step | Description |
|---|---|
| 1. Create an Account | If you don’t already have one, head to Qdrant Cloud and sign up. |
| 2. Set Up a Cluster | Log in to your account and find the Create New Cluster button on the dashboard. Follow the prompts to configure: - Select your preferred region. - Choose the free tier for testing. |
| 3. Secure Your Details | Once your cluster is ready, note these details: - Cluster URL (e.g., https://xxx-xxx-xxx.aws.cloud.qdrant.io) - API Key |
Save these securely for future use!
OpenAI API Configuration
Your OpenAI API key will power both embedding generation and language model interactions. Visit OpenAI’s platform and sign up for an account. In the API section of your dashboard, create a new API key. We’ll use the text-embedding-3-small model for embeddings and GPT-4 as the language model.
Brave Search
To enhance search capabilities, we’ll integrate Brave Search. Visit the Brave API and complete their API access request process to obtain an API key. This key will enable web search functionality for our agent.
For added security, store all API keys in a .env file.
OPENAI_API_KEY = <your-openai-api-key>
QDRANT_KEY = <your-qdrant-api-key>
QDRANT_URL = <your-qdrant-url>
BRAVE_API_KEY = <your-brave-api-key>
Then load the environment variables:
load_dotenv()
qdrant_key = os.getenv("QDRANT_KEY")
qdrant_url = os.getenv("QDRANT_URL")
brave_key = os.getenv("BRAVE_API_KEY")
Document Processing
Before we can create our agent, we need to process and store the documentation. We’ll be working with two datasets from Hugging Face: their general documentation and Transformers-specific documentation.
Here’s our document preprocessing function:
def preprocess_dataset(docs_list):
text_splitter = RecursiveCharacterTextSplitter.from_tiktoken_encoder(
chunk_size=700,
chunk_overlap=50,
disallowed_special=()
)
doc_splits = text_splitter.split_documents(docs_list)
return doc_splits
This function processes our documents by splitting them into manageable chunks, ensuring important context is preserved at the chunk boundaries through overlap. We’ll use the HuggingFaceDatasetLoader to load the datasets into Hugging Face documents.
hugging_face_doc = HuggingFaceDatasetLoader("m-ric/huggingface_doc","text")
transformers_doc = HuggingFaceDatasetLoader("m-ric/transformers_documentation_en","text")
In this demo, we are selecting the first 50 documents from the dataset and passing them to the processing function.
hf_splits = preprocess_dataset(hugging_face_doc.load()[:number_of_docs])
transformer_splits = preprocess_dataset(transformers_doc.load()[:number_of_docs])
Our splits are ready. Let’s create a collection in Qdrant to store them.
Defining the State
In LangGraph, a state refers to the data or information stored and maintained at a specific point during the execution of a process or a series of operations. States capture the intermediate or final results that the system needs to keep track of to manage and control the flow of tasks,
LangGraph works with a state-based system. We define our state like this:
class State(TypedDict):
messages: Annotated[list, add_messages]
Let’s build our tools.
Building the Tools
Our agent is equipped with three powerful tools:
- Hugging Face Documentation Retriever
- Transformers Documentation Retriever
- Web Search Tool
Let’s start by defining a retriever that takes documents and a collection name, then returns a retriever. The query is transformed into vectors using OpenAIEmbeddings.
def create_retriever(collection_name, doc_splits):
vectorstore = QdrantVectorStore.from_documents(
doc_splits,
OpenAIEmbeddings(model="text-embedding-3-small"),
url=qdrant_url,
api_key=qdrant_key,
collection_name=collection_name,
)
return vectorstore.as_retriever()
Both the Hugging Face documentation retriever and the Transformers documentation retriever use this same function. With this setup, it’s incredibly simple to create separate tools for each.
hf_retriever_tool = create_retriever_tool(
hf_retriever,
"retriever_hugging_face_documentation",
"Search and return information about hugging face documentation, it includes the guide and Python code.",
)
transformer_retriever_tool = create_retriever_tool(
transformer_retriever,
"retriever_transformer",
"Search and return information specifically about transformers library",
)
For web search, we create a simple yet effective tool using Brave Search:
@tool("web_search_tool")
def search_tool(query):
search = BraveSearch.from_api_key(api_key=brave_key, search_kwargs={"count": 3})
return search.run(query)
The search_tool function leverages the BraveSearch API to perform a search. It takes a query, retrieves the top 3 search results using the API key, and returns the results.
Next, we’ll set up and integrate our tools with a language model:
tools = [hf_retriever_tool, transformer_retriever_tool, search_tool]
tool_node = ToolNode(tools=tools)
llm = ChatOpenAI(model="gpt-4o", temperature=0)
llm_with_tools = llm.bind_tools(tools)
Here, the ToolNode class handles and orchestrates our tools:
class ToolNode:
def __init__(self, tools: list) -> None:
self.tools_by_name = {tool.name: tool for tool in tools}
def __call__(self, inputs: dict):
if messages := inputs.get("messages", []):
message = messages[-1]
else:
raise ValueError("No message found in input")
outputs = []
for tool_call in message.tool_calls:
tool_result = self.tools_by_name[tool_call["name"]].invoke(
tool_call["args"]
)
outputs.append(
ToolMessage(
content=json.dumps(tool_result),
name=tool_call["name"],
tool_call_id=tool_call["id"],
)
)
return {"messages": outputs}
The ToolNode class handles tool execution by initializing a list of tools and mapping tool names to their corresponding functions. It processes input dictionaries, extracts the last message, and checks for tool_calls from LLM tool-calling capability providers such as Anthropic, OpenAI, and others.
Routing and Decision Making
Our agent needs to determine when to use tools and when to end the cycle. This decision is managed by the routing function:
def route(state: State):
if isinstance(state, list):
ai_message = state[-1]
elif messages := state.get("messages", []):
ai_message = messages[-1]
else:
raise ValueError(f"No messages found in input state to tool_edge: {state}")
if hasattr(ai_message, "tool_calls") and len(ai_message.tool_calls) > 0:
return "tools"
return END
Putting It All Together: The Graph
Finally, we’ll construct the graph that ties everything together:
graph_builder = StateGraph(State)
graph_builder.add_node("agent", agent)
graph_builder.add_node("tools", tool_node)
graph_builder.add_conditional_edges(
"agent",
route,
{"tools": "tools", END: END},
)
graph_builder.add_edge("tools", "agent")
graph_builder.add_edge(START, "agent")
This is what the graph looks like:
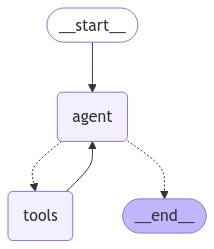
Fig. 3: Agentic RAG with LangGraph
Running the Agent
With everything set up, we can run our agent using a simple function:
def run_agent(user_input: str):
for event in graph.stream({"messages": [("user", user_input)]}):
for value in event.values():
print("Assistant:", value["messages"][-1].content)
Now, you’re ready to ask questions about Hugging Face and Transformers! Our agent will intelligently combine information from the documentation with web search results when needed.
For example, you can ask:
In the Transformers library, are there any multilingual models?
The agent will dive into the Transformers documentation, extract relevant details about multilingual models, and deliver a clear, comprehensive answer.
Here’s what the response might look like:
Yes, the Transformers library includes several multilingual models. Here are some examples:
BERT Multilingual:
Models like `bert-base-multilingual-uncased` can be used just like monolingual models.
XLM (Cross-lingual Language Model):
Models like `xlm-mlm-ende-1024` (English-German), `xlm-mlm-enfr-1024` (English-French), and others use language embeddings to specify the language used at inference.
M2M100:
Models like `facebook/m2m100_418M` and `facebook/m2m100_1.2B` are used for multilingual translation.
MBart:
Models like `facebook/mbart-large-50-one-to-many-mmt` and `facebook/mbart-large-50-many-to-many-mmt` are used for multilingual machine translation across 50 languages.
These models are designed to handle multiple languages and can be used for tasks like translation, classification, and more.
Conclusion
We’ve successfully implemented Agentic RAG. But this is just the beginning—there’s plenty more you can explore to take your system to the next level.
Agentic RAG is transforming how businesses connect data sources with AI, enabling smarter and more dynamic interactions. In this tutorial, you’ve learned how to build an Agentic RAG system that combines the power of LangGraph, Qdrant, and web search into one seamless workflow.
This system doesn’t just stop at retrieving relevant information from Hugging Face and Transformers documentation. It also smartly falls back to web search when needed, ensuring no query goes unanswered. With Qdrant as the vector database backbone, you get fast, scalable semantic search that excels at retrieving precise information—even from massive datasets.
To truly grasp the potential of this approach, why not apply these concepts to your own projects? Customize the template we’ve shared to fit your unique use case, and unlock the full potential of Agentic RAG for your business needs. The possibilities are endless.