Private RAG Information Extraction Engine
| Time: 90 min | Level: Advanced |
|---|
Handling private documents is a common task in many industries. Various businesses possess a large amount of unstructured data stored as huge files that must be processed and analyzed. Industry reports, financial analysis, legal documents, and many other documents are stored in PDF, Word, and other formats. Conversational chatbots built on top of RAG pipelines are one of the viable solutions for finding the relevant answers in such documents. However, if we want to extract structured information from these documents, and pass them to downstream systems, we need to use a different approach.
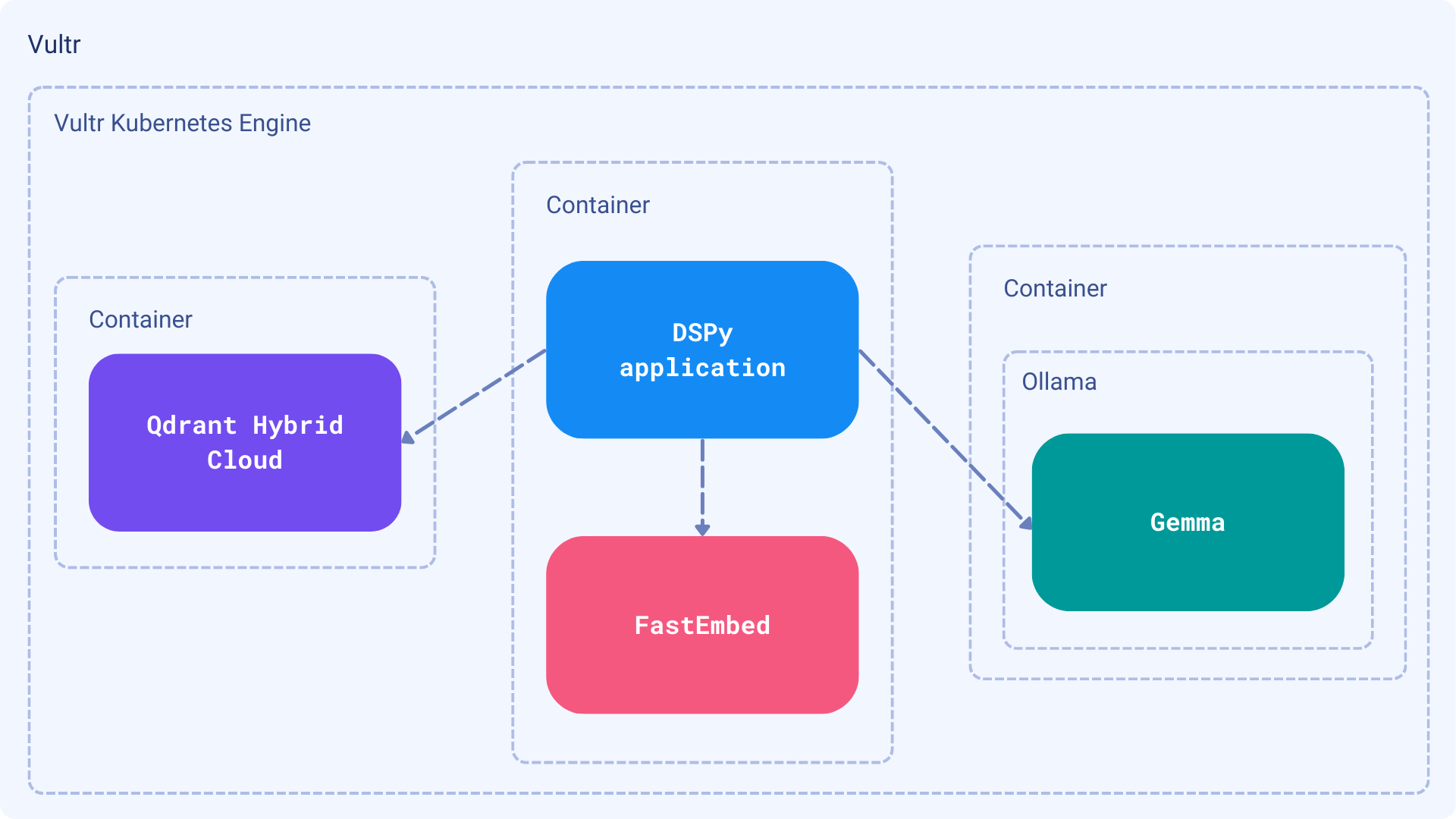
Information extraction is a process of structuring unstructured data into a format that can be easily processed by machines. In this tutorial, we will show you how to use DSPy to perform that process on a set of documents. Assuming we cannot send our data to an external service, we will use Ollama to run our own LLM model on our premises, using Vultr as a cloud provider. Qdrant, acting in this setup as a knowledge base providing the relevant pieces of documents for a given query, will also be hosted in the Hybrid Cloud mode on Vultr. The last missing piece, the DSPy application will be also running in the same environment. If you work in a regulated industry, or just need to keep your data private, this tutorial is for you.
Deploying Qdrant Hybrid Cloud on Vultr
All the services we are going to use in this tutorial will be running on Vultr Kubernetes Engine. That gives us a lot of flexibility in terms of scaling and managing the resources. Vultr manages the control plane and worker nodes and provides integration with other managed services such as Load Balancers, Block Storage, and DNS.
- To start using managed Kubernetes on Vultr, follow the platform-specific documentation.
- Once your Kubernetes clusters are up, you can begin deploying Qdrant Hybrid Cloud.
Installing the necessary packages
We are going to need a couple of Python packages to run our application. They might be installed together with the
dspy-ai package and qdrant extra:
pip install dspy-ai dspy-qdrant
Qdrant Hybrid Cloud
Our documentation contains a comprehensive guide on how to set up Qdrant in the Hybrid Cloud mode on Vultr. Please follow it carefully to get your Qdrant instance up and running. Once it’s done, we need to store the Qdrant URL and the API key in the environment variables. You can do it by running the following commands:
export QDRANT_URL="https://qdrant.example.com"
export QDRANT_API_KEY="your-api-key"
import os
os.environ["QDRANT_URL"] = "https://qdrant.example.com"
os.environ["QDRANT_API_KEY"] = "your-api-key"
DSPy is framework we are going to use. It’s integrated with Qdrant already, but it assumes you use FastEmbed to create the embeddings. DSPy does not provide a way to index the data, but leaves this task to the user. We are going to create a collection on our own, and fill it with the embeddings of our document chunks.
Data indexing
FastEmbed uses the BAAI/bge-small-en as the default embedding model. We are going to use it as well. Our collection
will be created automatically if we call the .add method on an existing QdrantClient instance. In this tutorial we
are not going to focus much on the document parsing, as there are plenty of tools that can help with that. The
unstructured library is one of the options you can launch on your
infrastructure. In our simplified example, we are going to use a list of strings as our documents. These are the
descriptions of the made up technical events. Each of them should contain the name of the event along with the location
and start and end dates.
documents = [
"Taking place in San Francisco, USA, from the 10th to the 12th of June, 2024, the Global Developers Conference is the annual gathering spot for developers worldwide, offering insights into software engineering, web development, and mobile applications.",
"The AI Innovations Summit, scheduled for 15-17 September 2024 in London, UK, aims at professionals and researchers advancing artificial intelligence and machine learning.",
"Berlin, Germany will host the CyberSecurity World Conference between November 5th and 7th, 2024, serving as a key forum for cybersecurity professionals to exchange strategies and research on threat detection and mitigation.",
"Data Science Connect in New York City, USA, occurring from August 22nd to 24th, 2024, connects data scientists, analysts, and engineers to discuss data science's innovative methodologies, tools, and applications.",
"Set for July 14-16, 2024, in Tokyo, Japan, the Frontend Developers Fest invites developers to delve into the future of UI/UX design, web performance, and modern JavaScript frameworks.",
"The Blockchain Expo Global, happening May 20-22, 2024, in Dubai, UAE, focuses on blockchain technology's applications, opportunities, and challenges for entrepreneurs, developers, and investors.",
"Singapore's Cloud Computing Summit, scheduled for October 3-5, 2024, is where IT professionals and cloud experts will convene to discuss strategies, architectures, and cloud solutions.",
"The IoT World Forum, taking place in Barcelona, Spain from December 1st to 3rd, 2024, is the premier conference for those focused on the Internet of Things, from smart cities to IoT security.",
"Los Angeles, USA, will become the hub for game developers, designers, and enthusiasts at the Game Developers Arcade, running from April 18th to 20th, 2024, to showcase new games and discuss development tools.",
"The TechWomen Summit in Sydney, Australia, from March 8-10, 2024, aims to empower women in tech with workshops, keynotes, and networking opportunities.",
"Seoul, South Korea's Mobile Tech Conference, happening from September 29th to October 1st, 2024, will explore the future of mobile technology, including 5G networks and app development trends.",
"The Open Source Summit, to be held in Helsinki, Finland from August 11th to 13th, 2024, celebrates open source technologies and communities, offering insights into the latest software and collaboration techniques.",
"Vancouver, Canada will play host to the VR/AR Innovation Conference from June 20th to 22nd, 2024, focusing on the latest in virtual and augmented reality technologies.",
"Scheduled for May 5-7, 2024, in London, UK, the Fintech Leaders Forum brings together experts to discuss the future of finance, including innovations in blockchain, digital currencies, and payment technologies.",
"The Digital Marketing Summit, set for April 25-27, 2024, in New York City, USA, is designed for marketing professionals and strategists to discuss digital marketing and social media trends.",
"EcoTech Symposium in Paris, France, unfolds over 2024-10-09 to 2024-10-11, spotlighting sustainable technologies and green innovations for environmental scientists, tech entrepreneurs, and policy makers.",
"Set in Tokyo, Japan, from 16th to 18th May '24, the Robotic Innovations Conference showcases automation, robotics, and AI-driven solutions, appealing to enthusiasts and engineers.",
"The Software Architecture World Forum in Dublin, Ireland, occurring 22-24 Sept 2024, gathers software architects and IT managers to discuss modern architecture patterns.",
"Quantum Computing Summit, convening in Silicon Valley, USA from 2024/11/12 to 2024/11/14, is a rendezvous for exploring quantum computing advancements with physicists and technologists.",
"From March 3 to 5, 2024, the Global EdTech Conference in London, UK, discusses the intersection of education and technology, featuring e-learning and digital classrooms.",
"Bangalore, India's NextGen DevOps Days, from 28 to 30 August 2024, is a hotspot for IT professionals keen on the latest DevOps tools and innovations.",
"The UX/UI Design Conference, slated for April 21-23, 2024, in New York City, USA, invites discussions on the latest in user experience and interface design among designers and developers.",
"Big Data Analytics Summit, taking place 2024 July 10-12 in Amsterdam, Netherlands, brings together data professionals to delve into big data analysis and insights.",
"Toronto, Canada, will see the HealthTech Innovation Forum from June 8 to 10, '24, focusing on technology's impact on healthcare with professionals and innovators.",
"Blockchain for Business Summit, happening in Singapore from 2024-05-02 to 2024-05-04, focuses on blockchain's business applications, from finance to supply chain.",
"Las Vegas, USA hosts the Global Gaming Expo from October 18th to 20th, 2024, a premiere event for game developers, publishers, and enthusiasts.",
"The Renewable Energy Tech Conference in Copenhagen, Denmark, from 2024/09/05 to 2024/09/07, discusses renewable energy innovations and policies.",
"Set for 2024 Apr 9-11 in Boston, USA, the Artificial Intelligence in Healthcare Summit gathers healthcare professionals to discuss AI's healthcare applications.",
"Nordic Software Engineers Conference, happening in Stockholm, Sweden from June 15 to 17, 2024, focuses on software development in the Nordic region.",
"The International Space Exploration Symposium, scheduled in Houston, USA from 2024-08-05 to 2024-08-07, invites discussions on space exploration technologies and missions."
]
We’ll be able to ask general questions, for example, about topics we are interested in or events happening in a specific location, but expect the results to be returned in a structured format.

Indexing in Qdrant is a single call if we have the documents defined:
client.add(
collection_name="document-parts",
documents=documents,
metadata=[{"document": document} for document in documents],
)
Our collection is ready to be queried. We can now move to the next step, which is setting up the Ollama model.
Ollama on Vultr
Ollama is a great tool for running the LLM models on your own infrastructure. It’s designed to be lightweight and easy to use, and an official Docker image is available. We can use it to run Ollama on our Vultr Kubernetes cluster. In case of LLMs we may have some special requirements, like a GPU, and Vultr provides the Vultr Kubernetes Engine for Cloud GPU so the model can be run on a specialized machine. Please refer to the official documentation to get Ollama up and running within your environment. Once it’s done, we need to store the Ollama URL in the environment variable:
export OLLAMA_URL="https://ollama.example.com"
os.environ["OLLAMA_URL"] = "https://ollama.example.com"
We will refer to this URL later on when configuring the Ollama model in our application.
Setting up the Large Language Model
We are going to use one of the lightweight LLMs available in Ollama, a gemma:2b model. It was developed by Google
DeepMind team and has 3B parameters. The Ollama version uses 4-bit quantization.
Installing the model is as simple as running the following command on the machine where Ollama is running:
ollama run gemma:2b
Ollama models are also integrated with DSPy, so we can use them directly in our application.
Implementing the information extraction pipeline
DSPy is a bit different from the other LLM frameworks. It’s designed to optimize the prompts and weights of LMs in a pipeline. It’s a bit like a compiler for LMs: you write a pipeline in a high-level language, and DSPy generates the prompts and weights for you. This means you can build complex systems without having to worry about the details of how to prompt your LMs, as DSPy will do that for you. It is somehow similar to PyTorch but for LLMs.
First of all, we will define the Language Model we are going to use:
import dspy
gemma_model = dspy.OllamaLocal(
model="gemma:2b",
base_url=os.environ.get("OLLAMA_URL"),
max_tokens=500,
)
Similarly, we have to define connection to our Qdrant Hybrid Cloud cluster:
from dspy_qdrant import QdrantRM
from qdrant_client import QdrantClient, models
client = QdrantClient(
os.environ.get("QDRANT_URL"),
api_key=os.environ.get("QDRANT_API_KEY"),
)
qdrant_retriever = QdrantRM(
qdrant_collection_name="document-parts",
qdrant_client=client,
)
Finally, both components have to be configured in DSPy with a simple call to one of the functions:
dspy.configure(lm=gemma_model, rm=qdrant_retriever)
Application logic
There is a concept of signatures which defines input and output formats of the pipeline. We are going to define a simple signature for the event:
class Event(dspy.Signature):
description = dspy.InputField(
desc="Textual description of the event, including name, location and dates"
)
event_name = dspy.OutputField(desc="Name of the event")
location = dspy.OutputField(desc="Location of the event")
start_date = dspy.OutputField(desc="Start date of the event, YYYY-MM-DD")
end_date = dspy.OutputField(desc="End date of the event, YYYY-MM-DD")
It is designed to derive the structured information from the textual description of the event. Now, we can build our
module that will use it, along with Qdrant and Ollama model. Let’s call it EventExtractor:
class EventExtractor(dspy.Module):
def __init__(self):
super().__init__()
# Retrieve module to get relevant documents
self.retriever = dspy.Retrieve(k=3)
# Predict module for the created signature
self.predict = dspy.Predict(Event)
def forward(self, query: str):
# Retrieve the most relevant documents
results = self.retriever.forward(query)
# Try to extract events from the retrieved documents
events = []
for document in results.passages:
event = self.predict(description=document)
events.append(event)
return events
The logic is simple: we retrieve the most relevant documents from Qdrant, and then try to extract the structured
information from them using the Event signature. We can simply call it and see the results:
extractor = EventExtractor()
extractor.forward("Blockchain events close to Europe")
Output:
[
Prediction(
event_name='Event Name: Blockchain Expo Global',
location='Dubai, UAE',
start_date='2024-05-20',
end_date='2024-05-22'
),
Prediction(
event_name='Event Name: Blockchain for Business Summit',
location='Singapore',
start_date='2024-05-02',
end_date='2024-05-04'
),
Prediction(
event_name='Event Name: Open Source Summit',
location='Helsinki, Finland',
start_date='2024-08-11',
end_date='2024-08-13'
)
]
The task was solved successfully, even without any optimization. However, each of the events has the “Event Name: " prefix that we might want to remove. DSPy allows optimizing the module, so we can improve the results. Optimization might be done in different ways, and it’s well covered in the DSPy documentation.
We are not going to go through the optimization process in this tutorial. However, we encourage you to experiment with it, as it might significantly improve the performance of your pipeline.
Created module might be easily stored on a specific path, and loaded later on:
extractor.save("event_extractor")
To load, just create an instance of the module and call the load method:
second_extractor = EventExtractor()
second_extractor.load("event_extractor")
This is especially useful when you optimize the module, as the optimized version might be stored and loaded later on without redoing the optimization process each time you run the application.
Deploying the extraction pipeline
Vultr gives us a lot of flexibility in terms of deploying the applications. Perfectly, we would use the Kubernetes cluster we set up earlier to run it. The deployment is as simple as running any other Python application. This time we don’t need a GPU, as Ollama is already running on a separate machine, and DSPy just interacts with it.
Wrapping up
In this tutorial, we showed you how to set up a private environment for information extraction using DSPy, Ollama, and Qdrant. All the components might be securely hosted on the Vultr cloud, giving you full control over your data.