Blog-Reading Chatbot with GPT-4o
| Time: 90 min | Level: Advanced | GitHub |
|---|
In this tutorial, you will build a RAG system that combines blog content ingestion with the capabilities of semantic search. OpenAI’s GPT-4o LLM is powerful, but scaling its use requires us to supply context systematically.
RAG enhances the LLM’s generation of answers by retrieving relevant documents to aid the question-answering process. This setup showcases the integration of advanced search and AI language processing to improve information retrieval and generation tasks.
A notebook for this tutorial is available on GitHub.
Data Privacy and Sovereignty: RAG applications often rely on sensitive or proprietary internal data. Running the entire stack within your own environment becomes crucial for maintaining control over this data. Qdrant Hybrid Cloud deployed on Scaleway addresses this need perfectly, offering a secure, scalable platform that still leverages the full potential of RAG. Scaleway offers serverless Functions and serverless Jobs, both of which are ideal for embedding creation in large-scale RAG cases.
Components
- Cloud Host: Scaleway on managed Kubernetes for compatibility with Qdrant Hybrid Cloud.
- Vector Database: Qdrant Hybrid Cloud as the vector search engine for retrieval.
- LLM: GPT-4o, developed by OpenAI is utilized as the generator for producing answers.
- Framework: LangChain for extensive RAG capabilities.
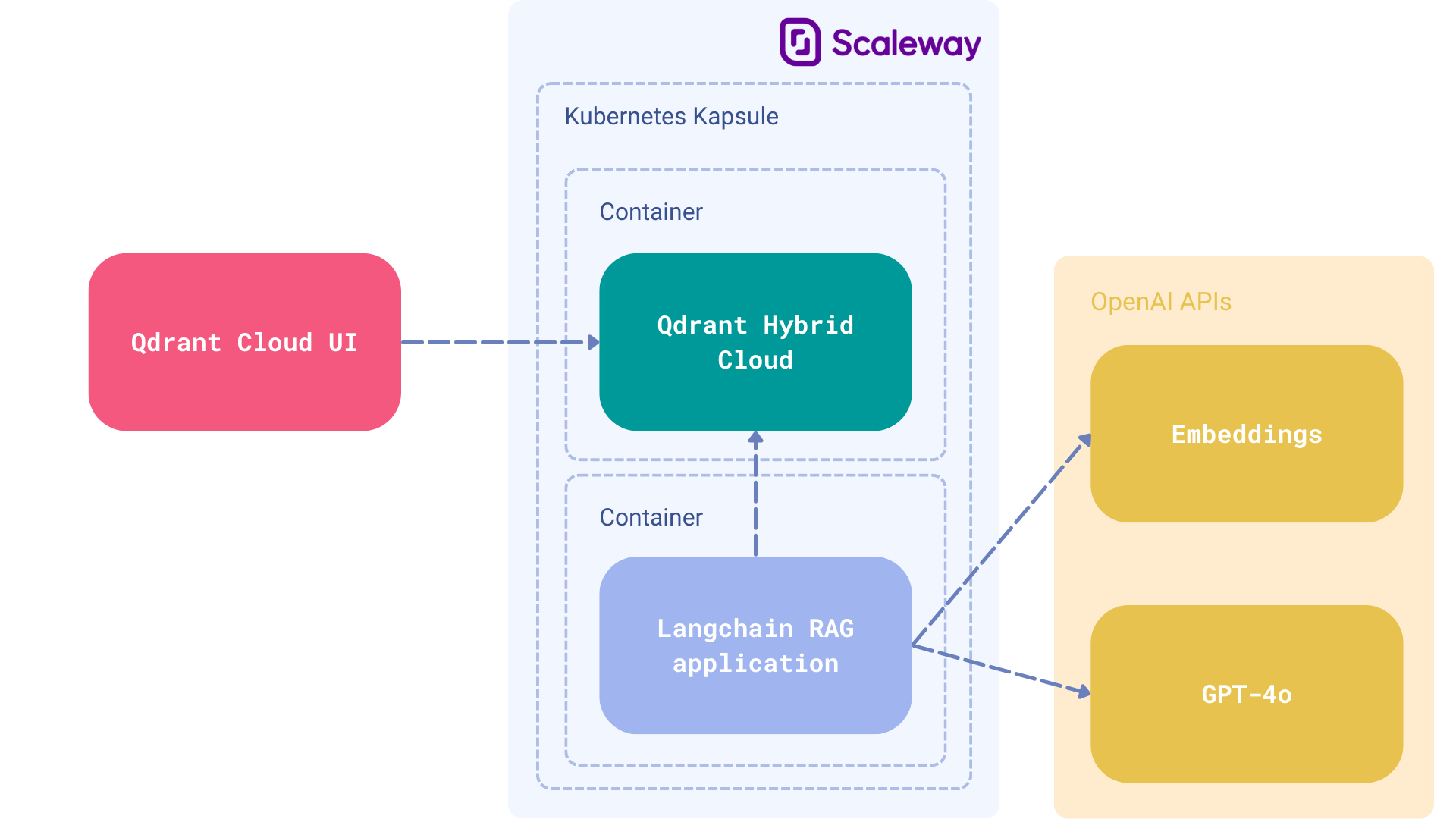
LangChain supports a wide range of LLMs, and GPT-4o is used as the main generator in this tutorial. You can easily swap it out for your preferred model that might be launched on your premises to complete the fully private setup. For the sake of simplicity, we used the OpenAI APIs, but LangChain makes the transition seamless.
Deploying Qdrant Hybrid Cloud on Scaleway
Scaleway Kapsule and Kosmos are managed Kubernetes services from Scaleway. They abstract away the complexities of managing and operating a Kubernetes cluster. The primary difference being, Kapsule clusters are composed solely of Scaleway Instances. Whereas, a Kosmos cluster is a managed multi-cloud Kubernetes engine that allows you to connect instances from any cloud provider to a single managed Control-Plane.
- To start using managed Kubernetes on Scaleway, follow the platform-specific documentation.
- Once your Kubernetes clusters are up, you can begin deploying Qdrant Hybrid Cloud.
Prerequisites
To prepare the environment for working with Qdrant and related libraries, it’s necessary to install all required Python packages. This can be done using Poetry, a tool for dependency management and packaging in Python. The code snippet imports various libraries essential for the tasks ahead, including bs4 for parsing HTML and XML documents, langchain and its community extensions for working with language models and document loaders, and Qdrant for vector storage and retrieval. These imports lay the groundwork for utilizing Qdrant alongside other tools for natural language processing and machine learning tasks.
Qdrant will be running on a specific URL and access will be restricted by the API key. Make sure to store them both as environment variables as well:
export QDRANT_URL="https://qdrant.example.com"
export QDRANT_API_KEY="your-api-key"
Optional: Whenever you use LangChain, you can also configure LangSmith, which will help us trace, monitor and debug LangChain applications. You can sign up for LangSmith here.
export LANGCHAIN_TRACING_V2=true
export LANGCHAIN_API_KEY="your-api-key"
export LANGCHAIN_PROJECT="your-project" # if not specified, defaults to "default"
Now you can get started:
import getpass
import os
import bs4
from langchain import hub
from langchain_community.document_loaders import WebBaseLoader
from langchain_qdrant import Qdrant
from langchain_core.output_parsers import StrOutputParser
from langchain_core.runnables import RunnablePassthrough
from langchain_openai import ChatOpenAI, OpenAIEmbeddings
from langchain_text_splitters import RecursiveCharacterTextSplitter
Set up the OpenAI API key:
os.environ["OPENAI_API_KEY"] = getpass.getpass()
Initialize the language model:
llm = ChatOpenAI(model="gpt-4o")
It is here that we configure both the Embeddings and LLM. You can replace this with your own models using Ollama or other services. Scaleway has some great L4 GPU Instances you can use for compute here.
Download and parse data
To begin working with blog post contents, the process involves loading and parsing the HTML content. This is achieved using urllib and BeautifulSoup, which are tools designed for such tasks. After the content is loaded and parsed, it is indexed using Qdrant, a powerful tool for managing and querying vector data. The code snippet demonstrates how to load, chunk, and index the contents of a blog post by specifying the URL of the blog and the specific HTML elements to parse. This step is crucial for preparing the data for further processing and analysis with Qdrant.
# Load, chunk and index the contents of the blog.
loader = WebBaseLoader(
web_paths=("https://lilianweng.github.io/posts/2023-06-23-agent/",),
bs_kwargs=dict(
parse_only=bs4.SoupStrainer(
class_=("post-content", "post-title", "post-header")
)
),
)
docs = loader.load()
Chunking data
When dealing with large documents, such as a blog post exceeding 42,000 characters, it’s crucial to manage the data efficiently for processing. Many models have a limited context window and struggle with long inputs, making it difficult to extract or find relevant information. To overcome this, the document is divided into smaller chunks. This approach enhances the model’s ability to process and retrieve the most pertinent sections of the document effectively.
In this scenario, the document is split into chunks using the RecursiveCharacterTextSplitter with a specified chunk size and overlap. This method ensures that no critical information is lost between chunks. Following the splitting, these chunks are then indexed into Qdrant—a vector database for efficient similarity search and storage of embeddings. The Qdrant.from_documents function is utilized for indexing, with documents being the split chunks and embeddings generated through OpenAIEmbeddings. The entire process is facilitated within an in-memory database, signifying that the operations are performed without the need for persistent storage, and the collection is named “lilianweng” for reference.
This chunking and indexing strategy significantly improves the management and retrieval of information from large documents, making it a practical solution for handling extensive texts in data processing workflows.
text_splitter = RecursiveCharacterTextSplitter(chunk_size=1000, chunk_overlap=200)
text_splitter = RecursiveCharacterTextSplitter(chunk_size=1000, chunk_overlap=200)
splits = text_splitter.split_documents(docs)
vectorstore = Qdrant.from_documents(
documents=splits,
embedding=OpenAIEmbeddings(),
collection_name="lilianweng",
url=os.environ["QDRANT_URL"],
api_key=os.environ["QDRANT_API_KEY"],
)
Retrieve and generate content
The vectorstore is used as a retriever to fetch relevant documents based on vector similarity. The hub.pull("rlm/rag-prompt") function is used to pull a specific prompt from a repository, which is designed to work with retrieved documents and a question to generate a response.
The format_docs function formats the retrieved documents into a single string, preparing them for further processing. This formatted string, along with a question, is passed through a chain of operations. Firstly, the context (formatted documents) and the question are processed by the retriever and the prompt. Then, the result is fed into a large language model (llm) for content generation. Finally, the output is parsed into a string format using StrOutputParser().
This chain of operations demonstrates a sophisticated approach to information retrieval and content generation, leveraging both the semantic understanding capabilities of vector search and the generative prowess of large language models.
Now, retrieve and generate data using relevant snippets from the blog:
retriever = vectorstore.as_retriever()
prompt = hub.pull("rlm/rag-prompt")
def format_docs(docs):
return "\n\n".join(doc.page_content for doc in docs)
rag_chain = (
{"context": retriever | format_docs, "question": RunnablePassthrough()}
| prompt
| llm
| StrOutputParser()
)
Invoking the RAG Chain
rag_chain.invoke("What is Task Decomposition?")
Next steps:
We built a solid foundation for a simple chatbot, but there is still a lot to do. If you want to make the system production-ready, you should consider implementing the mechanism into your existing stack. We recommend
Our vector database can easily be hosted on Scaleway, our trusted Qdrant Hybrid Cloud partner. This means that Qdrant can be run from your Scaleway region, but the database itself can still be managed from within Qdrant Cloud’s interface. Both products have been tested for compatibility and scalability, and we recommend their managed Kubernetes service. Their French deployment regions e.g. France are excellent for network latency and data sovereignty. For hosted GPUs, try rendering with L4 GPU instances.
If you have any questions, feel free to ask on our Discord community.