Region-Specific Contract Management System
| Time: 90 min | Level: Advanced |
|---|
Contract management benefits greatly from Retrieval Augmented Generation (RAG), streamlining the handling of lengthy business contract texts. With AI assistance, complex questions can be asked and well-informed answers generated, facilitating efficient document management. This proves invaluable for businesses with extensive relationships, like shipping companies, construction firms, and consulting practices. Access to such contracts is often restricted to authorized team members due to security and regulatory requirements, such as GDPR in Europe, necessitating secure storage practices.
Companies want their data to be kept and processed within specific geographical boundaries. For that reason, this RAG-centric tutorial focuses on dealing with a region-specific cloud provider. You will set up a contract management system using Aleph Alpha’s embeddings and LLM. You will host everything on STACKIT, a German business cloud provider. On this platform, you will run Qdrant Hybrid Cloud as well as the rest of your RAG application. This setup will ensure that your data is stored and processed in Germany.
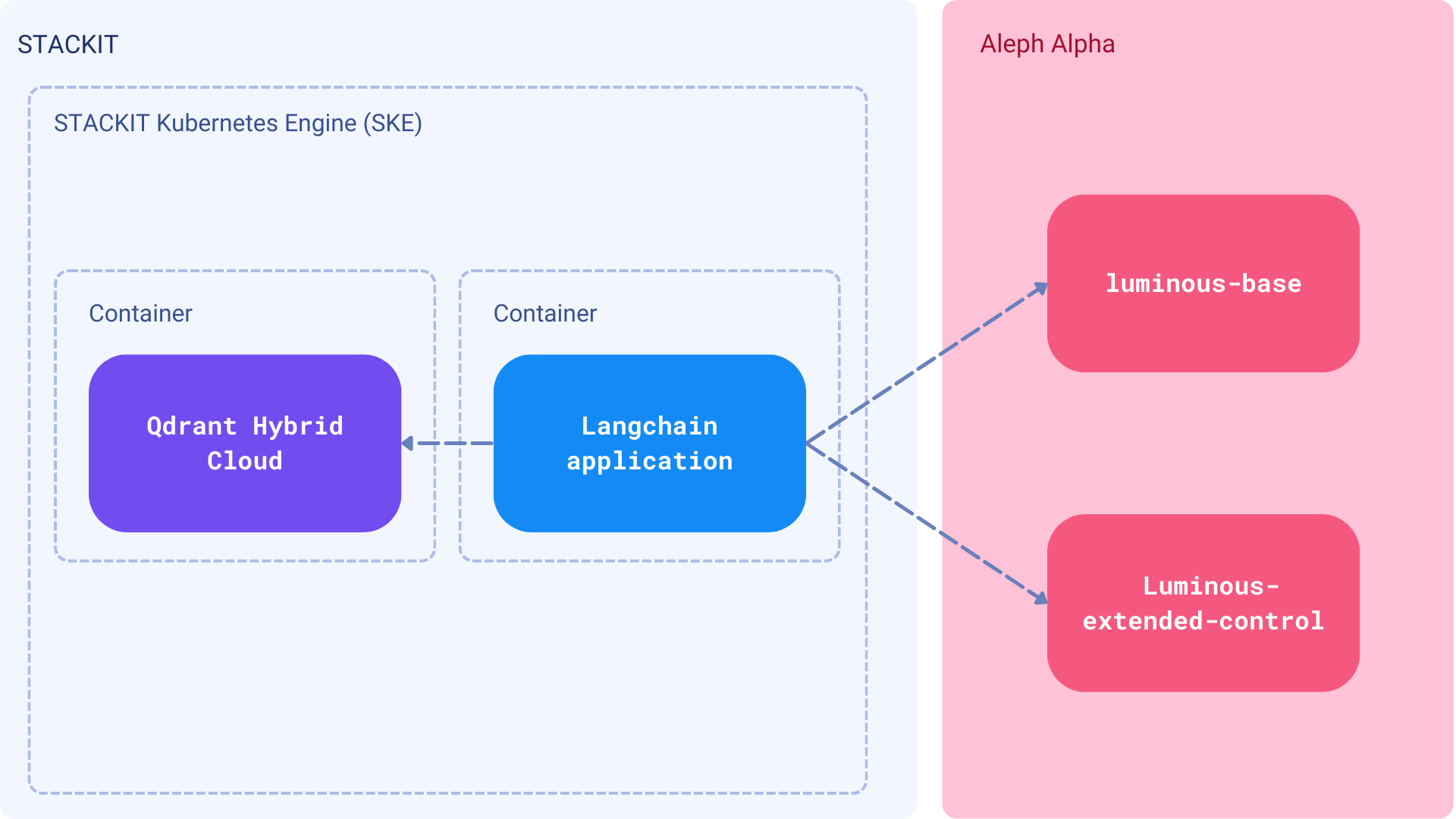
Components
A contract management platform is not a simple CLI tool, but an application that should be available to all team members. It needs an interface to upload, search, and manage the documents. Ideally, the system should be integrated with org’s existing stack, and the permissions/access controls inherited from LDAP or Active Directory.
Note: In this tutorial, we are going to build a solid foundation for such a system. However, it is up to your organization’s setup to implement the entire solution.
- Dataset - a collection of documents, using different formats, such as PDF or DOCx, scraped from internet
- Asymmetric semantic embeddings - Aleph Alpha embedding to convert the queries and the documents into vectors
- Large Language Model - the Luminous-extended-control model, but you can play with a different one from the Luminous family
- Qdrant Hybrid Cloud - a knowledge base to store the vectors and search over the documents
- STACKIT - a German business cloud to run the Qdrant Hybrid Cloud and the application processes
We will implement the process of uploading the documents, converting them into vectors, and storing them in Qdrant. Then, we will build a search interface to query the documents and get the answers. All that, assuming the user interacts with the system with some set of permissions, and can only access the documents they are allowed to.
Prerequisites
Aleph Alpha account
Since you will be using Aleph Alpha’s models, sign up with their managed service and obtain an API token. Once you have it ready, store it as an environment variable:
export ALEPH_ALPHA_API_KEY="<your-token>"
import os
os.environ["ALEPH_ALPHA_API_KEY"] = "<your-token>"
Qdrant Hybrid Cloud on STACKIT
Please refer to our documentation to see how to deploy Qdrant Hybrid Cloud on STACKIT. Once you finish the deployment, you will have the API endpoint to interact with the Qdrant server. Let’s store it in the environment variable as well:
export QDRANT_URL="https://qdrant.example.com"
export QDRANT_API_KEY="your-api-key"
os.environ["QDRANT_URL"] = "https://qdrant.example.com"
os.environ["QDRANT_API_KEY"] = "your-api-key"
Qdrant will be running on a specific URL and access will be restricted by the API key. Make sure to store them both as environment variables as well:
Optional: Whenever you use LangChain, you can also configure LangSmith, which will help us trace, monitor and debug LangChain applications. You can sign up for LangSmith here.
export LANGCHAIN_TRACING_V2=true
export LANGCHAIN_API_KEY="your-api-key"
export LANGCHAIN_PROJECT="your-project" # if not specified, defaults to "default"
Implementation
To build the application, we can use the official SDKs of Aleph Alpha and Qdrant. However, to streamline the process let’s use LangChain. This framework is already integrated with both services, so we can focus our efforts on developing business logic.
Qdrant collection
Aleph Alpha embeddings are high dimensional vectors by default, with a dimensionality of 5120. However, a pretty
unique feature of that model is that they might be compressed to a size of 128, with a small drop in accuracy
performance (4-6%, according to the docs). Qdrant can store even the original vectors easily, and this sounds like a
good idea to enable Binary Quantization to save space and
make the retrieval faster. Let’s create a collection with such settings:
from qdrant_client import QdrantClient, models
client = QdrantClient(
location=os.environ["QDRANT_URL"],
api_key=os.environ["QDRANT_API_KEY"],
)
client.create_collection(
collection_name="contracts",
vectors_config=models.VectorParams(
size=5120,
distance=models.Distance.COSINE,
quantization_config=models.BinaryQuantization(
binary=models.BinaryQuantizationConfig(
always_ram=True,
)
)
),
)
We are going to use the contracts collection to store the vectors of the documents. The always_ram flag is set to
True to keep the quantized vectors in RAM, which will speed up the search process. We also wanted to restrict access
to the individual documents, so only users with the proper permissions can see them. In Qdrant that should be solved by
adding a payload field that defines who can access the document. We’ll call this field roles and set it to an array
of strings with the roles that can access the document.
client.create_payload_index(
collection_name="contracts",
field_name="metadata.roles",
field_schema=models.PayloadSchemaType.KEYWORD,
)
Since we use Langchain, the roles field is a nested field of the metadata, so we have to define it as
metadata.roles. The schema says that the field is a keyword, which means it is a string or an array of strings. We are
going to use the name of the customers as the roles, so the access control will be based on the customer name.
Ingestion pipeline
Semantic search systems rely on high-quality data as their foundation. With the unstructured integration of Langchain, ingestion of various document formats like PDFs, Microsoft Word files, and PowerPoint presentations becomes effortless. However, it’s crucial to split the text intelligently to avoid converting entire documents into vectors; instead, they should be divided into meaningful chunks. Subsequently, the extracted documents are converted into vectors using Aleph Alpha embeddings and stored in the Qdrant collection.
Let’s start by defining the components and connecting them together:
embeddings = AlephAlphaAsymmetricSemanticEmbedding(
model="luminous-base",
aleph_alpha_api_key=os.environ["ALEPH_ALPHA_API_KEY"],
normalize=True,
)
qdrant = Qdrant(
client=client,
collection_name="contracts",
embeddings=embeddings,
)
Now it’s high time to index our documents. Each of the documents is a separate file, and we also have to know the customer name to set the access control properly. There might be several roles for a single document, so let’s keep them in a list.
documents = {
"data/Data-Processing-Agreement_STACKIT_Cloud_version-1.2.pdf": ["stackit"],
"data/langchain-terms-of-service.pdf": ["langchain"],
}
This is how the documents might look like:

Each has to be split into chunks first; there is no silver bullet. Our chunking algorithm will be simple and based on recursive splitting, with the maximum chunk size of 500 characters and the overlap of 100 characters.
from langchain_text_splitters import RecursiveCharacterTextSplitter
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=500,
chunk_overlap=100,
)
Now we can iterate over the documents, split them into chunks, convert them into vectors with Aleph Alpha embedding model, and store them in the Qdrant.
from langchain_community.document_loaders.unstructured import UnstructuredFileLoader
for document_path, roles in documents.items():
document_loader = UnstructuredFileLoader(file_path=document_path)
# Unstructured loads each file into a single Document object
loaded_documents = document_loader.load()
for doc in loaded_documents:
doc.metadata["roles"] = roles
# Chunks will have the same metadata as the original document
document_chunks = text_splitter.split_documents(loaded_documents)
# Add the documents to the Qdrant collection
qdrant.add_documents(document_chunks, batch_size=20)
Our collection is filled with data, and we can start searching over it. In a real-world scenario, the ingestion process should be automated and triggered by the new documents uploaded to the system. Since we already use Qdrant Hybrid Cloud running on Kubernetes, we can easily deploy the ingestion pipeline as a job to the same environment. On STACKIT, you probably use the STACKIT Kubernetes Engine (SKE) and launch it in a container. The Compute Engine is also an option, but everything depends on the specifics of your organization.
Search application
Specialized Document Management Systems have a lot of features, but semantic search is not yet a standard. We are going to build a simple search mechanism which could be possibly integrated with the existing system. The search process is quite simple: we convert the query into a vector using the same Aleph Alpha model, and then search for the most similar documents in the Qdrant collection. The access control is also applied, so the user can only see the documents they are allowed to.
We start with creating an instance of the LLM of our choice, and set the maximum number of tokens to 200, as the default value is 64, which might be too low for our purposes.
from langchain.llms.aleph_alpha import AlephAlpha
llm = AlephAlpha(
model="luminous-extended-control",
aleph_alpha_api_key=os.environ["ALEPH_ALPHA_API_KEY"],
maximum_tokens=200,
)
Then, we can glue the components together and build the search process. RetrievalQA is a class that takes implements
the Question Retrieval process, with a specified retriever and Large Language Model. The instance of Qdrant might be
converted into a retriever, with additional filter that will be passed to the similarity_search method. The filter
is created as in a regular Qdrant query, with the roles field set to the
user’s roles.
user_roles = ["stackit", "aleph-alpha"]
qdrant_retriever = qdrant.as_retriever(
search_kwargs={
"filter": models.Filter(
must=[
models.FieldCondition(
key="metadata.roles",
match=models.MatchAny(any=user_roles)
)
]
)
}
)
We set the user roles to stackit and aleph-alpha, so the user can see the documents that are accessible to these
customers, but not to the others. The final step is to create the RetrievalQA instance and use it to search over the
documents, with the custom prompt.
from langchain.prompts import PromptTemplate
from langchain.chains.retrieval_qa.base import RetrievalQA
prompt_template = """
Question: {question}
Answer the question using the Source. If there's no answer, say "NO ANSWER IN TEXT".
Source: {context}
### Response:
"""
prompt = PromptTemplate(
template=prompt_template, input_variables=["context", "question"]
)
retrieval_qa = RetrievalQA.from_chain_type(
llm=llm,
chain_type="stuff",
retriever=qdrant_retriever,
return_source_documents=True,
chain_type_kwargs={"prompt": prompt},
)
response = retrieval_qa.invoke({"query": "What are the rules of performing the audit?"})
print(response["result"])
Output:
The rules for performing the audit are as follows:
1. The Customer must inform the Contractor in good time (usually at least two weeks in advance) about any and all circumstances related to the performance of the audit.
2. The Customer is entitled to perform one audit per calendar year. Any additional audits may be performed if agreed with the Contractor and are subject to reimbursement of expenses.
3. If the Customer engages a third party to perform the audit, the Customer must obtain the Contractor's consent and ensure that the confidentiality agreements with the third party are observed.
4. The Contractor may object to any third party deemed unsuitable.
There are some other parameters that might be tuned to optimize the search process. The k parameter defines how many
documents should be returned, but Langchain allows us also to control the retrieval process by choosing the type of the
search operation. The default is similarity, which is just vector search, but we can also use mmr which stands for
Maximal Marginal Relevance. It is a technique to diversify the search results, so the user gets the most relevant
documents, but also the most diverse ones. The mmr search is slower, but might be more user-friendly.
Our search application is ready, and we can deploy it to the same environment as the ingestion pipeline on STACKIT. The same rules apply here, so you can use the SKE or the Compute Engine, depending on the specifics of your organization.
Next steps
We built a solid foundation for the contract management system, but there is still a lot to do. If you want to make the system production-ready, you should consider implementing the mechanism into your existing stack. If you have any questions, feel free to ask on our Discord community.