RAG System for Employee Onboarding
Public websites are a great way to share information with a wide audience. However, finding the right information can be challenging, if you are not familiar with the website’s structure or the terminology used. That’s what the search bar is for, but it is not always easy to formulate a query that will return the desired results, if you are not yet familiar with the content. This is even more important in a corporate environment, and for the new employees, who are just starting to learn the ropes, and don’t even know how to ask the right questions yet. You may have even the best intranet pages, but onboarding is more than just reading the documentation, it is about understanding the processes. Semantic search can help with finding right resources easier, but wouldn’t it be easier to just chat with the website, like you would with a colleague?
Technological advancements have made it possible to interact with websites using natural language. This tutorial will guide you through the process of integrating Cohere’s language models with Qdrant to enable natural language search on your documentation. We are going to use LangChain as an orchestrator. Everything will be hosted on Oracle Cloud Infrastructure (OCI), so you can scale your application as needed, and do not send your data to third parties. That is especially important when you are working with confidential or sensitive data.
Building up the application
Our application will consist of two main processes: indexing and searching. LangChain will glue everything together, as we will use a few components, including Cohere and Qdrant, as well as some OCI services. Here is a high-level overview of the architecture:
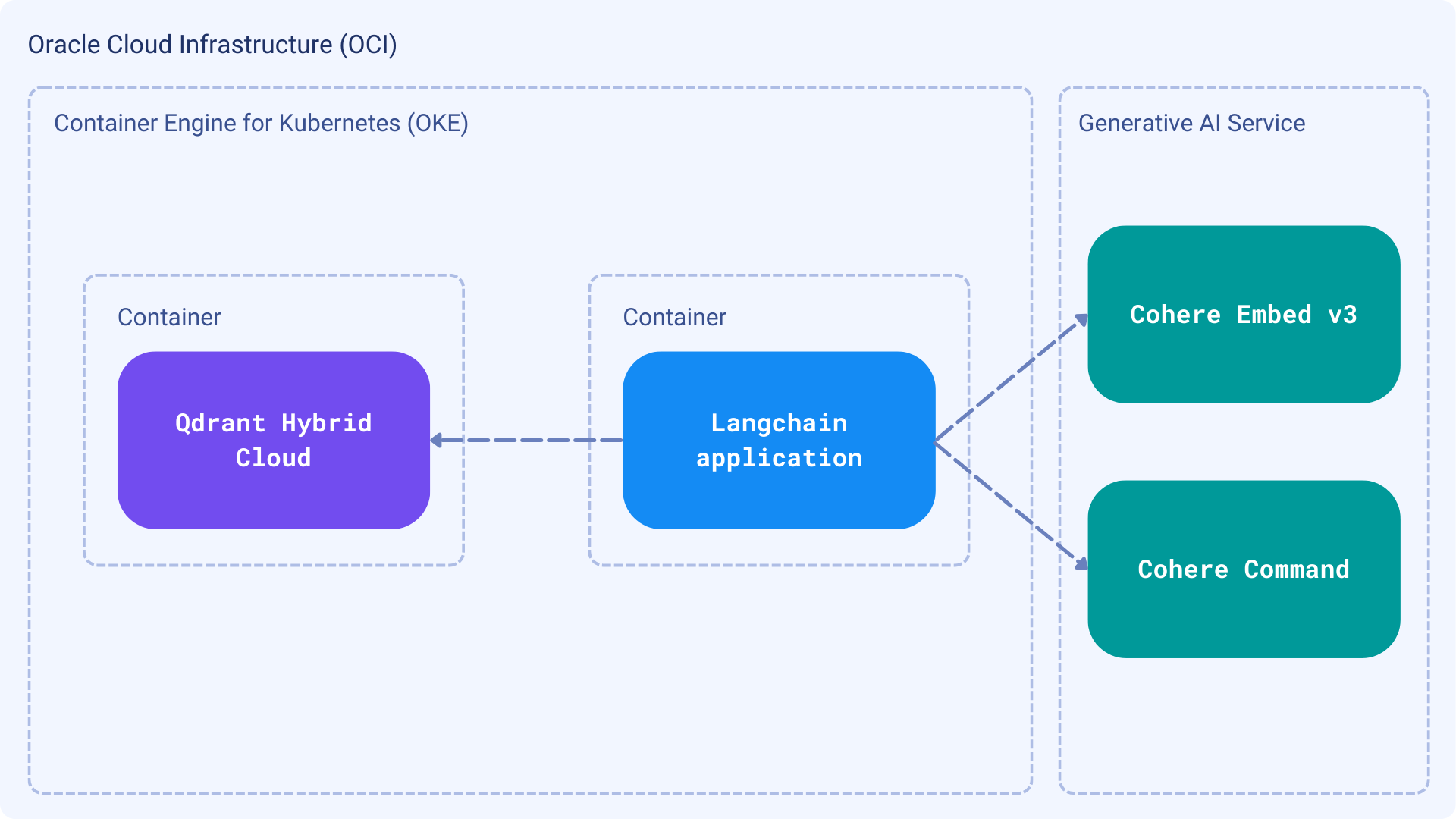
Prerequisites
Before we dive into the implementation, make sure to set up all the necessary accounts and tools.
Libraries
We are going to use a few Python libraries. Of course, LangChain will be our main framework, but the Cohere models on OCI are accessible via the OCI SDK. Let’s install all the necessary libraries:
pip install langchain oci qdrant-client langchainhub
Oracle Cloud
Our application will be fully running on Oracle Cloud Infrastructure (OCI). It’s up to you to choose how you want to deploy your application. Qdrant Hybrid Cloud will be running in your Kubernetes cluster running on Oracle Cloud (OKE), so all the processes might be also deployed there. You can get started with signing up for an account on Oracle Cloud.
Cohere models are available on OCI as a part of the Generative AI Service. We need both the Generation models and the Embedding models. Please follow the linked tutorials to grasp the basics of using Cohere models there.
Accessing the models programmatically requires knowing the compartment OCID. Please refer to the documentation that describes how to find it. For the further reference, we will assume that the compartment OCID is stored in the environment variable:
export COMPARTMENT_OCID="<your-compartment-ocid>"
import os
os.environ["COMPARTMENT_OCID"] = "<your-compartment-ocid>"
Qdrant Hybrid Cloud
Qdrant Hybrid Cloud running on Oracle Cloud helps you build a solution without sending your data to external services. Our documentation provides a step-by-step guide on how to deploy Qdrant Hybrid Cloud on Oracle Cloud.
Qdrant will be running on a specific URL and access will be restricted by the API key. Make sure to store them both as environment variables as well:
export QDRANT_URL="https://qdrant.example.com"
export QDRANT_API_KEY="your-api-key"
Optional: Whenever you use LangChain, you can also configure LangSmith, which will help us trace, monitor and debug LangChain applications. You can sign up for LangSmith here.
export LANGCHAIN_TRACING_V2=true
export LANGCHAIN_API_KEY="your-api-key"
export LANGCHAIN_PROJECT="your-project" # if not specified, defaults to "default"
Now you can get started:
import os
os.environ["QDRANT_URL"] = "https://qdrant.example.com"
os.environ["QDRANT_API_KEY"] = "your-api-key"
Let’s create the collection that will store the indexed documents. We will use the qdrant-client library, and our
collection will be named oracle-cloud-website. Our embedding model, cohere.embed-english-v3.0, produces embeddings
of size 1024, and we have to specify that when creating the collection.
from qdrant_client import QdrantClient, models
client = QdrantClient(
location=os.environ.get("QDRANT_URL"),
api_key=os.environ.get("QDRANT_API_KEY"),
)
client.create_collection(
collection_name="oracle-cloud-website",
vectors_config=models.VectorParams(
size=1024,
distance=models.Distance.COSINE,
),
)
Indexing process
We have all the necessary tools set up, so let’s start with the indexing process. We will use the Cohere Embedding models to convert the text into vectors, and then store them in Qdrant. LangChain is integrated with OCI Generative AI Service, so we can easily access the models.
Our dataset will be fairly simple, as it will consist of the questions and answers from the Oracle Cloud Free Tier FAQ page.
Questions and answers are presented in an HTML format, but we don’t want to manually extract the text and adapt it for
each subpage. Instead, we will use the WebBaseLoader that just loads the HTML content from given URL and converts it
to text.
from langchain_community.document_loaders.web_base import WebBaseLoader
loader = WebBaseLoader("https://www.oracle.com/cloud/free/faq/")
documents = loader.load()
Our documents is a list with just a single element, which is the text of the whole page. We need to split it into
meaningful parts, so we will use the RecursiveCharacterTextSplitter component. It will try to keep all paragraphs (and
then sentences, and then words) together as long as possible, as those would generically seem to be the strongest
semantically related pieces of text. The chunk size and overlap are both parameters that can be adjusted to fit the
specific use case.
from langchain_text_splitters import RecursiveCharacterTextSplitter
splitter = RecursiveCharacterTextSplitter(chunk_size=300, chunk_overlap=100)
split_documents = splitter.split_documents(documents)
Our documents might be now indexed, but we need to convert them into vectors. Let’s configure the embeddings so the
cohere.embed-english-v3.0 is used. Not all the regions support the Generative AI Service, so we need to specify the
region where the models are stored. We will use the us-chicago-1, but please check the
documentation for the most up-to-date
list of supported regions.
from langchain_community.embeddings.oci_generative_ai import OCIGenAIEmbeddings
embeddings = OCIGenAIEmbeddings(
model_id="cohere.embed-english-v3.0",
service_endpoint="https://inference.generativeai.us-chicago-1.oci.oraclecloud.com",
compartment_id=os.environ.get("COMPARTMENT_OCID"),
)
Now we can embed the documents and store them in Qdrant. We will create an instance of Qdrant and add the split
documents to the collection.
from langchain.vectorstores.qdrant import Qdrant
qdrant = Qdrant(
client=client,
collection_name="oracle-cloud-website",
embeddings=embeddings,
)
qdrant.add_documents(split_documents, batch_size=20)
Our documents should be now indexed and ready for searching. Let’s move to the next step.
Speaking to the website
The intended method of interaction with the website is through the chatbot. Large Language Model, in our case Cohere Command, will be answering user’s questions based on the relevant documents that Qdrant will return using the question as a query. Our LLM is also hosted on OCI, so we can access it similarly to the embedding model:
from langchain_community.llms.oci_generative_ai import OCIGenAI
llm = OCIGenAI(
model_id="cohere.command",
service_endpoint="https://inference.generativeai.us-chicago-1.oci.oraclecloud.com",
compartment_id=os.environ.get("COMPARTMENT_OCID"),
)
Connection to Qdrant might be established in the same way as we did during the indexing process. We can use it to create a retrieval chain, which implements the question-answering process. The retrieval chain also requires an additional chain that will combine retrieved documents before sending them to an LLM.
from langchain.chains.combine_documents import create_stuff_documents_chain
from langchain.chains.retrieval import create_retrieval_chain
from langchain import hub
retriever = qdrant.as_retriever()
combine_docs_chain = create_stuff_documents_chain(
llm=llm,
# Default prompt is loaded from the hub, but we can also modify it
prompt=hub.pull("langchain-ai/retrieval-qa-chat"),
)
retrieval_qa_chain = create_retrieval_chain(
retriever=retriever,
combine_docs_chain=combine_docs_chain,
)
response = retrieval_qa_chain.invoke({"input": "What is the Oracle Cloud Free Tier?"})
The output of the .invoke method is a dictionary-like structure with the query and answer, but we can also access the
source documents used to generate the response. This might be useful for debugging or for further processing.
{
'input': 'What is the Oracle Cloud Free Tier?',
'context': [
Document(
page_content='* Free Tier is generally available in regions where commercial Oracle Cloud Infrastructure service is available. See the data regions page for detailed service availability (the exact regions available for Free Tier may differ during the sign-up process). The US$300 cloud credit is available in',
metadata={
'language': 'en-US',
'source': 'https://www.oracle.com/cloud/free/faq/',
'title': "FAQ on Oracle's Cloud Free Tier",
'_id': 'c8cf98e0-4b88-4750-be42-4157495fed2c',
'_collection_name': 'oracle-cloud-website'
}
),
Document(
page_content='Oracle Cloud Free Tier allows you to sign up for an Oracle Cloud account which provides a number of Always Free services and a Free Trial with US$300 of free credit to use on all eligible Oracle Cloud Infrastructure services for up to 30 days. The Always Free services are available for an unlimited',
metadata={
'language': 'en-US',
'source': 'https://www.oracle.com/cloud/free/faq/',
'title': "FAQ on Oracle's Cloud Free Tier",
'_id': 'dc291430-ff7b-4181-944a-39f6e7a0de69',
'_collection_name': 'oracle-cloud-website'
}
),
Document(
page_content='Oracle Cloud Free Tier does not include SLAs. Community support through our forums is available to all customers. Customers using only Always Free resources are not eligible for Oracle Support. Limited support is available for Oracle Cloud Free Tier with Free Trial credits. After you use all of',
metadata={
'language': 'en-US',
'source': 'https://www.oracle.com/cloud/free/faq/',
'title': "FAQ on Oracle's Cloud Free Tier",
'_id': '9e831039-7ccc-47f7-9301-20dbddd2fc07',
'_collection_name': 'oracle-cloud-website'
}
),
Document(
page_content='looking to test things before moving to cloud, a student wanting to learn, or an academic developing curriculum in the cloud, Oracle Cloud Free Tier enables you to learn, explore, build and test for free.',
metadata={
'language': 'en-US',
'source': 'https://www.oracle.com/cloud/free/faq/',
'title': "FAQ on Oracle's Cloud Free Tier",
'_id': 'e2dc43e1-50ee-4678-8284-6df60a835cf5',
'_collection_name': 'oracle-cloud-website'
}
)
],
'answer': ' Oracle Cloud Free Tier is a subscription that gives you access to Always Free services and a Free Trial with $300 of credit that can be used on all eligible Oracle Cloud Infrastructure services for up to 30 days. \n\nThrough this Free Tier, you can learn, explore, build, and test for free. It is aimed at those who want to experiment with cloud services before making a commitment, as wellTheir use cases range from testing prior to cloud migration to learning and academic curriculum development. '
}
Other experiments
Asking the basic questions is just the beginning. What you want to avoid is a hallucination, where the model generates an answer that is not based on the actual content. The default prompt of LangChain should already prevent this, but you might still want to check it. Let’s ask a question that is not directly answered on the FAQ page:
response = retrieval_qa.invoke({
"input": "Is Oracle Generative AI Service included in the free tier?"
})
Output:
Oracle Generative AI Services are not specifically mentioned as being available in the free tier. As per the text, the $300 free credit can be used on all eligible services for up to 30 days. To confirm if Oracle Generative AI Services are included in the free credit offer, it is best to check the official Oracle Cloud website or contact their support.
It seems that Cohere Command model could not find the exact answer in the provided documents, but it tried to interpret the context and provide a reasonable answer, without making up the information. This is a good sign that the model is not hallucinating in that case.
Wrapping up
This tutorial has shown how to integrate Cohere’s language models with Qdrant to enable natural language search on your website. We have used LangChain as an orchestrator, and everything was hosted on Oracle Cloud Infrastructure (OCI). Real world would require integrating this mechanism into your organization’s systems, but we built a solid foundation that can be further developed.