Build a GraphRAG Agent with Neo4j and Qdrant

| Time: 30 min | Level: Intermediate | Output: GitHub |
|---|
To make Artificial Intelligence (AI) systems more intelligent and reliable, we face a paradox: Large Language Models (LLMs) possess remarkable reasoning capabilities, yet they struggle to connect information in ways humans find intuitive. While groundbreaking, Retrieval-Augmented Generation (RAG) approaches often fall short when tasked with complex information synthesis. When asked to connect disparate pieces of information or understand holistic concepts across large documents, these systems frequently miss crucial connections that would be obvious to human experts.
To solve these problems, Microsoft introduced GraphRAG, which uses Knowledge Graphs (KGs) instead of vectors as a context for LLMs. GraphRAG depends mainly on LLMs for creating KGs and querying them. However, this reliance on LLMs can lead to many problems. We will address these challenges by combining vector databases with graph-based databases.
This tutorial will demonstrate how to build a GraphRAG system with vector search using Neo4j and Qdrant.
| Additional Materials |
|---|
| This advanced tutorial is based on our original integration doc: Neo4j - Qdrant Integration |
| The output for this tutorial is in our GitHub Examples repo: Neo4j - Qdrant Agent in Python |
Watch the Video
RAG & Its Challenges
RAG combines retrieval-based and generative AI to enhance LLMs with relevant, up-to-date information from a knowledge base, like a vector database. However, RAG faces several challenges:
- Understanding Context: Models may misinterpret queries, particularly when the context is complex or ambiguous, leading to incorrect or irrelevant answers.
- Balancing Similarity vs. Relevance: RAG systems can struggle to ensure that retrieved information is similar and contextually relevant.
- Answer Completeness: Traditional RAGs might not be able to capture all relevant details for complex queries that require LLMs to find relationships in the context that are not explicitly present.
Introduction to GraphRAG
Unlike RAG, which typically relies on document retrieval, GraphRAG builds knowledge graphs (KGs) to capture entities and their relationships. For datasets or use cases that demand human-level intelligence from an AI system, GraphRAG offers a promising solution:
- It can follow chains of relationships to answer complex queries, making it suitable for better reasoning beyond simple document retrieval.
- The graph structure allows a deeper understanding of the context, leading to more accurate and relevant responses.
The workflow of GraphRAG is as follows:
- The LLM analyzes the dataset to identify entities (people, places, organizations) and their relationships, creating a comprehensive knowledge graph where entities are nodes and their connections form edges.
- A bottom-up clustering algorithm organizes the KG into hierarchical semantic groups. This creates meaningful segments of related information, enabling understanding at different levels of abstraction.
- GraphRAG uses both the KG and semantic clusters to select a relevant context for the LLM when answering queries.
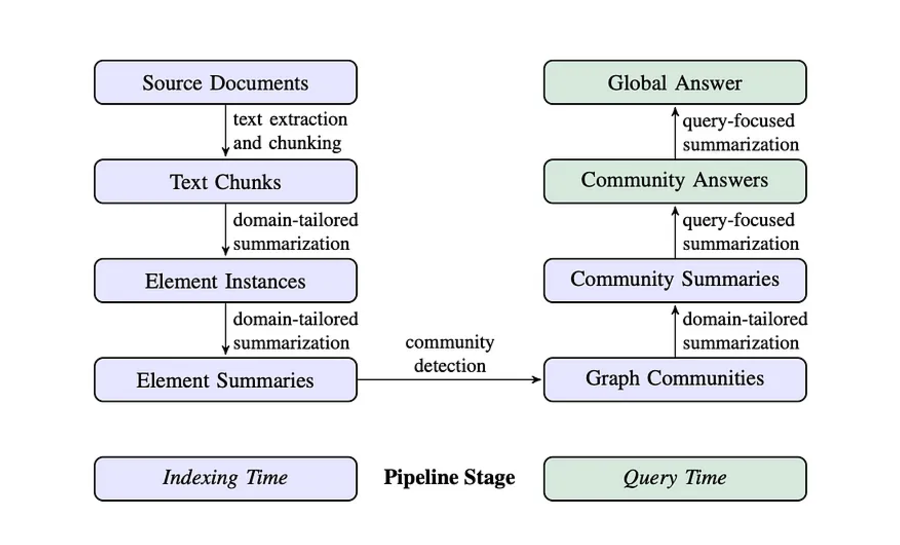
Fig 1: A Complete Picture of GraphRAG Ingestion and Retrieval
Challenges of GraphRAG
Despite its advantages, the LLM-centric GraphRAG approach faces several challenges:
- KG Construction with LLMs: Since the LLM is responsible for constructing the knowledge graph, there are risks such as inconsistencies, propagation of biases or errors, and lack of control over the ontology used. However, we used a LLM to extract the ontology in our implementation.
- Querying KG with LLMs: Once the graph is constructed, an LLM translates the human query into Cypher (Neo4j’s declarative query language). However, crafting complex queries in Cypher may result in inaccurate outcomes.
- Scalability & Cost Consideration: To be practical, applications must be both scalable and cost-effective. Relying on LLMs increases costs and decreases scalability, as they are used every time data is added, queried, or generated.
To address these challenges, a more controlled and structured knowledge representation system may be required for GraphRAG to function optimally at scale.
Architecture Overview
The architecture has two main components: Ingestion and Retrieval & Generation. Ingestion processes raw data into structured knowledge and vector representations, while Retrieval and Generation enable efficient querying and response generation.
This process is divided into two steps: Ingestion, where data is prepared and stored, and Retrieval and Generation, where the prepared data is queried and utilized. Let’s start with Ingestion.
Ingestion
The GraphRAG ingestion pipeline combines a Graph Database and a Vector Database to improve RAG workflows.
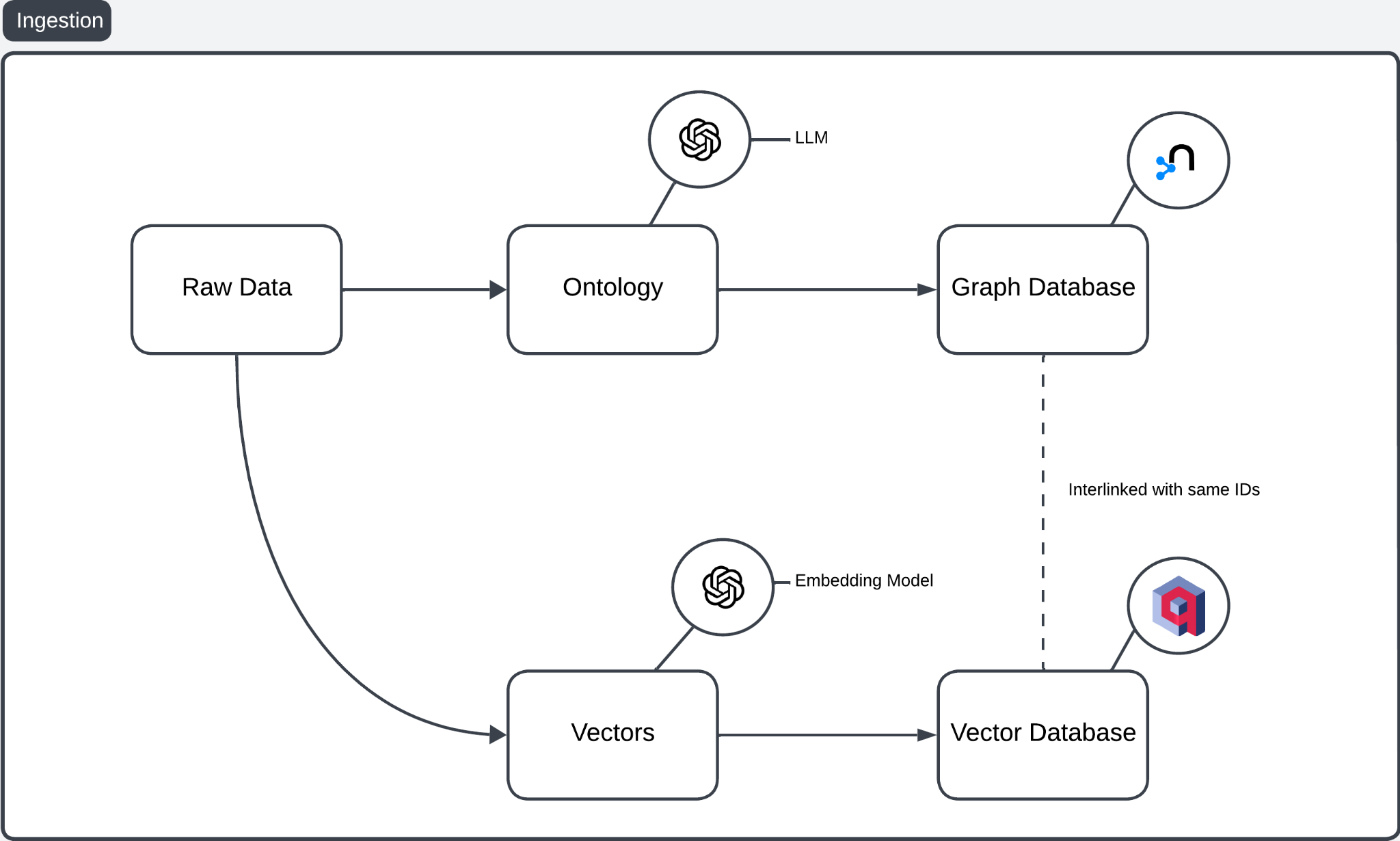
Fig 2: Overview of Ingestion Pipeline
Let’s break it down:
- Raw Data: Serves as the foundation, comprising unstructured or structured content.
- Ontology Creation: An LLM processes the raw data into an ontology, structuring entities, relationships, and hierarchies. Better approaches exist to extracting more structured information from raw data, like using NER to identify the names of people, organizations, and places. Unlike LLMs, this method creates.
- Graph Database: The ontology is stored in a Graph database to capture complex relationships.
- Vector Embeddings: An Embedding model converts the raw data into high-dimensional vectors capturing semantic similarities.
- Vector Database: These embeddings are stored in a Vector database for similarity-based retrieval.
- Database Interlinking: The Graph database (e.g., Neo4j) and Vector database (e.g., Qdrant) share unique IDs, enabling cross-referencing between ontology-based and vector-based results.
Retrieval & Generation
The Retrieval and Generation process is designed to handle user queries by leveraging both semantic search and graph-based context extraction.
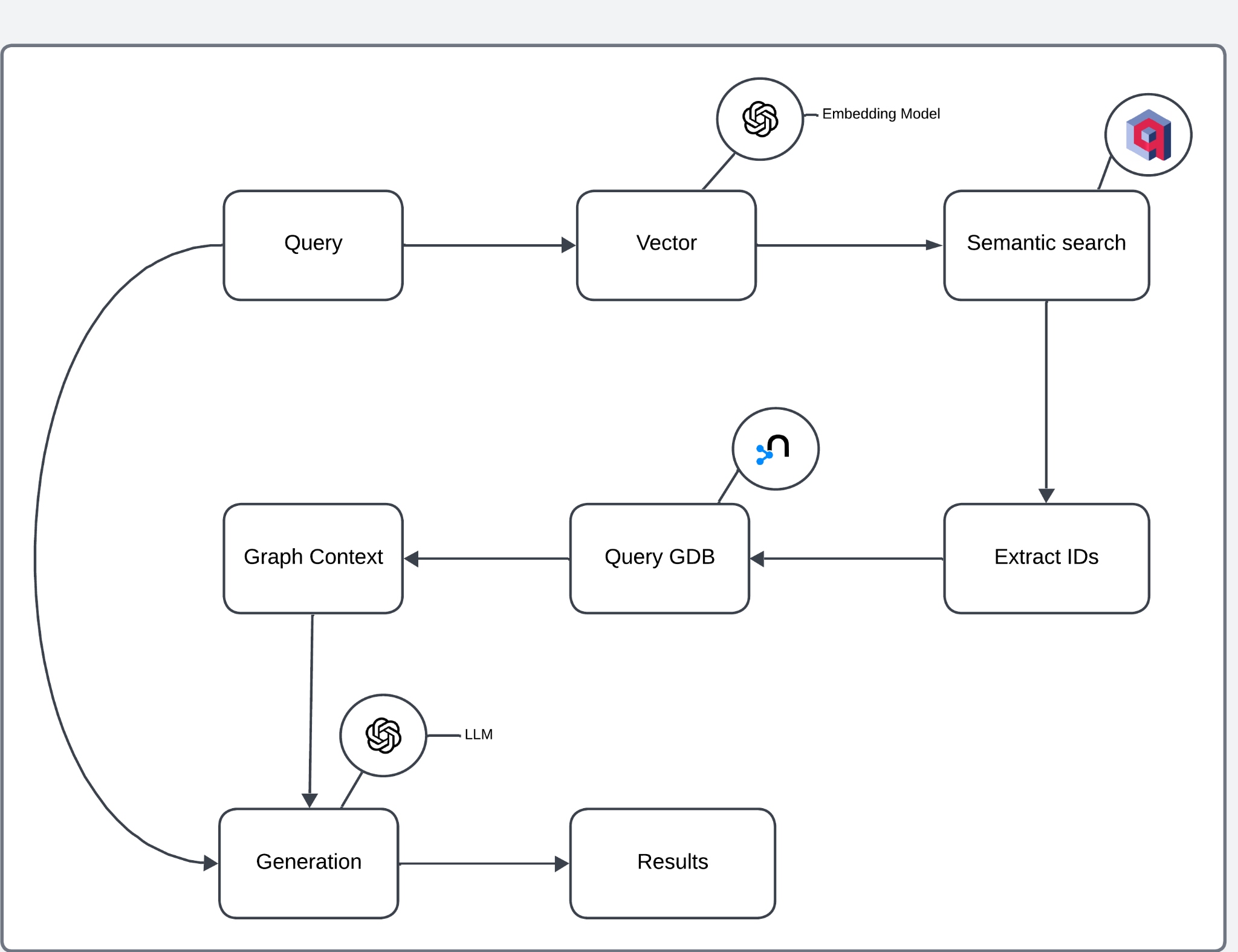
Fig 3: Overview of Retrieval and Generation Pipeline
The architecture can be broken down into the following steps:
- Query Vectorization: An embedding model converts The user query into a high-dimensional vector.
- Semantic Search: The vector performs a similarity-based search in the Vector database, retrieving relevant documents or entries.
- ID Extraction: Extracted IDs from the semantic search results are used to query the Graph database.
- Graph Context Retrieval: The Graph database provides contextual information, including relationships and entities linked to the extracted IDs.
- Response Generation: The context retrieved from the graph is passed to an LLM to generate a final response.
- Results: The generated response is returned to the user.
This architecture combines the strengths of both databases:
- Semantic Search with Vector Database: The user query is first processed semantically to identify the most relevant data points without needing explicit keyword matches.
- Contextual Expansion with Graph Database: IDs or entities retrieved from the vector database query the graph database for detailed relationships, enriching the retrieved data with structured context.
- Enhanced Generation: The architecture combines semantic relevance (from the vector database) and graph-based context to enable the LLM to generate more informed, accurate, and contextually rich responses.
Implementation
We’ll walk through a complete pipeline that ingests data into Neo4j and Qdrant, retrieves relevant data, and generates responses using an LLM based on the retrieved graph context.
The main components of this pipeline include data ingestion (to Neo4j and Qdrant), retrieval, and generation steps.
Prerequisites
These are the tutorial prerequisites, which are divided into setup, imports, and initialization of the two DBs.
Setup
Let’s start with setting up instances with Qdrant and Neo4j.
Qdrant Setup
To create a Qdrant instance, you can use their managed service (Qdrant Cloud) or set up a self-hosted cluster. For simplicity, we will use Qdrant cloud:
- Go to Qdrant Cloud and sign up or log in.
- Once logged in, click on Create New Cluster.
- Follow the on-screen instructions to create your cluster.
- Once your cluster is created, you’ll be given a Cluster URL and API Key, which you will use in the client to interact with Qdrant.
Neo4j Setup
To set up a Neo4j instance, you can use Neo4j Aura (cloud service) or host it yourself. We will use Neo4j Aura:
- Go to Neo4j Aura and sign up/log in.
- After setting up, an instance will be created if it is the first time.
- After the database is set up, you’ll receive a connection URI, username, and password.
We can add the following in the .env file for security purposes.
Imports
First, we import the required libraries for working with Neo4j, Qdrant, OpenAI, and other utility functions.
from neo4j import GraphDatabase
from qdrant_client import QdrantClient, models
from dotenv import load_dotenv
from pydantic import BaseModel
from openai import OpenAI
from collections import defaultdict
from neo4j_graphrag.retrievers import QdrantNeo4jRetriever
import uuid
import os
- Neo4j: Used to store and query the graph database.
- Qdrant: A vector database used for semantic similarity search.
- dotenv: Loads environment variables for credentials and API keys.
- Pydantic: Ensures data is structured properly when interacting with the graph data.
- OpenAI: Interfaces with the OpenAI API to generate responses and embeddings.
- neo4j_graphrag: A helper package to retrieve data from both Qdrant and Neo4j.
Setting Up Environment Variables
Before initializing the clients, we load the necessary credentials from environment variables.
# Load environment variables
load_dotenv()
# Get credentials from environment variables
qdrant_key = os.getenv("QDRANT_KEY")
qdrant_url = os.getenv("QDRANT_URL")
neo4j_uri = os.getenv("NEO4J_URI")
neo4j_username = os.getenv("NEO4J_USERNAME")
neo4j_password = os.getenv("NEO4J_PASSWORD")
openai_key = os.getenv("OPENAI_API_KEY")
This ensures that sensitive information (like API keys and database credentials) is securely stored in environment variables.
Initializing Neo4j and Qdrant Clients
Now, we initialize the Neo4j and Qdrant clients using the credentials.
# Initialize Neo4j driver
neo4j_driver = GraphDatabase.driver(neo4j_uri, auth=(neo4j_username, neo4j_password))
# Initialize Qdrant client
qdrant_client = QdrantClient(
url=qdrant_url,
api_key=qdrant_key
)
- Neo4j: We set up a connection to the Neo4j graph database.
- Qdrant: We initialize the connection to the Qdrant vector store.
This will connect with Neo4j and Qdrant, and we can now start with Ingestion.
Ingestion
We will follow the workflow of the ingestion pipeline presented in the architecture section. Let’s examine it implementation-wise.
Defining Output Parser
The single and GraphComponents classes structure the LLM’s responses into a usable format.
class single(BaseModel):
node: str
target_node: str
relationship: str
class GraphComponents(BaseModel):
graph: list[single]
These classes help ensure that data from the OpenAI LLM is parsed correctly into the graph components (nodes and relationships).
Defining OpenAI Client and LLM Parser Function
We now initialize the OpenAI client and define a function to send prompts to the LLM and parse its responses.
client = OpenAI()
def openai_llm_parser(prompt):
completion = client.chat.completions.create(
model="gpt-4o-2024-08-06",
response_format={"type": "json_object"},
messages=[
{
"role": "system",
"content":
""" You are a precise graph relationship extractor. Extract all
relationships from the text and format them as a JSON object
with this exact structure:
{
"graph": [
{"node": "Person/Entity",
"target_node": "Related Entity",
"relationship": "Type of Relationship"},
...more relationships...
]
}
Include ALL relationships mentioned in the text, including
implicit ones. Be thorough and precise. """
},
{
"role": "user",
"content": prompt
}
]
)
return GraphComponents.model_validate_json(completion.choices[0].message.content)
This function sends a prompt to the LLM, asking it to extract graph components (nodes and relationships) from the provided text. The response is parsed into structured graph data.
Extracting Graph Components
The function extract_graph_components processes raw data, extracting the nodes and relationships as graph components.
def extract_graph_components(raw_data):
prompt = f"Extract nodes and relationships from the following text:\n{raw_data}"
parsed_response = openai_llm_parser(prompt) # Assuming this returns a list of dictionaries
parsed_response = parsed_response.graph # Assuming the 'graph' structure is a key in the parsed response
nodes = {}
relationships = []
for entry in parsed_response:
node = entry.node
target_node = entry.target_node # Get target node if available
relationship = entry.relationship # Get relationship if available
# Add nodes to the dictionary with a unique ID
if node not in nodes:
nodes[node] = str(uuid.uuid4())
if target_node and target_node not in nodes:
nodes[target_node] = str(uuid.uuid4())
# Add relationship to the relationships list with node IDs
if target_node and relationship:
relationships.append({
"source": nodes[node],
"target": nodes[target_node],
"type": relationship
})
return nodes, relationships
This function takes raw data, uses the LLM to parse it into graph components, and then assigns unique IDs to nodes and relationships.
Ingesting Data to Neo4j
The function ingest_to_neo4j ingests the extracted graph data (nodes and relationships) into Neo4j.
def ingest_to_neo4j(nodes, relationships):
"""
Ingest nodes and relationships into Neo4j.
"""
with neo4j_driver.session() as session:
# Create nodes in Neo4j
for name, node_id in nodes.items():
session.run(
"CREATE (n:Entity {id: $id, name: $name})",
id=node_id,
name=name
)
# Create relationships in Neo4j
for relationship in relationships:
session.run(
"MATCH (a:Entity {id: $source_id}), (b:Entity {id: $target_id}) "
"CREATE (a)-[:RELATIONSHIP {type: $type}]->(b)",
source_id=relationship["source"],
target_id=relationship["target"],
type=relationship["type"]
)
return nodes
Here, we create nodes and relationships in the Neo4j graph database. Nodes are entities, and relationships link these entities.
This will ingest the data into Neo4j and on a sample dataset it looks something like this:
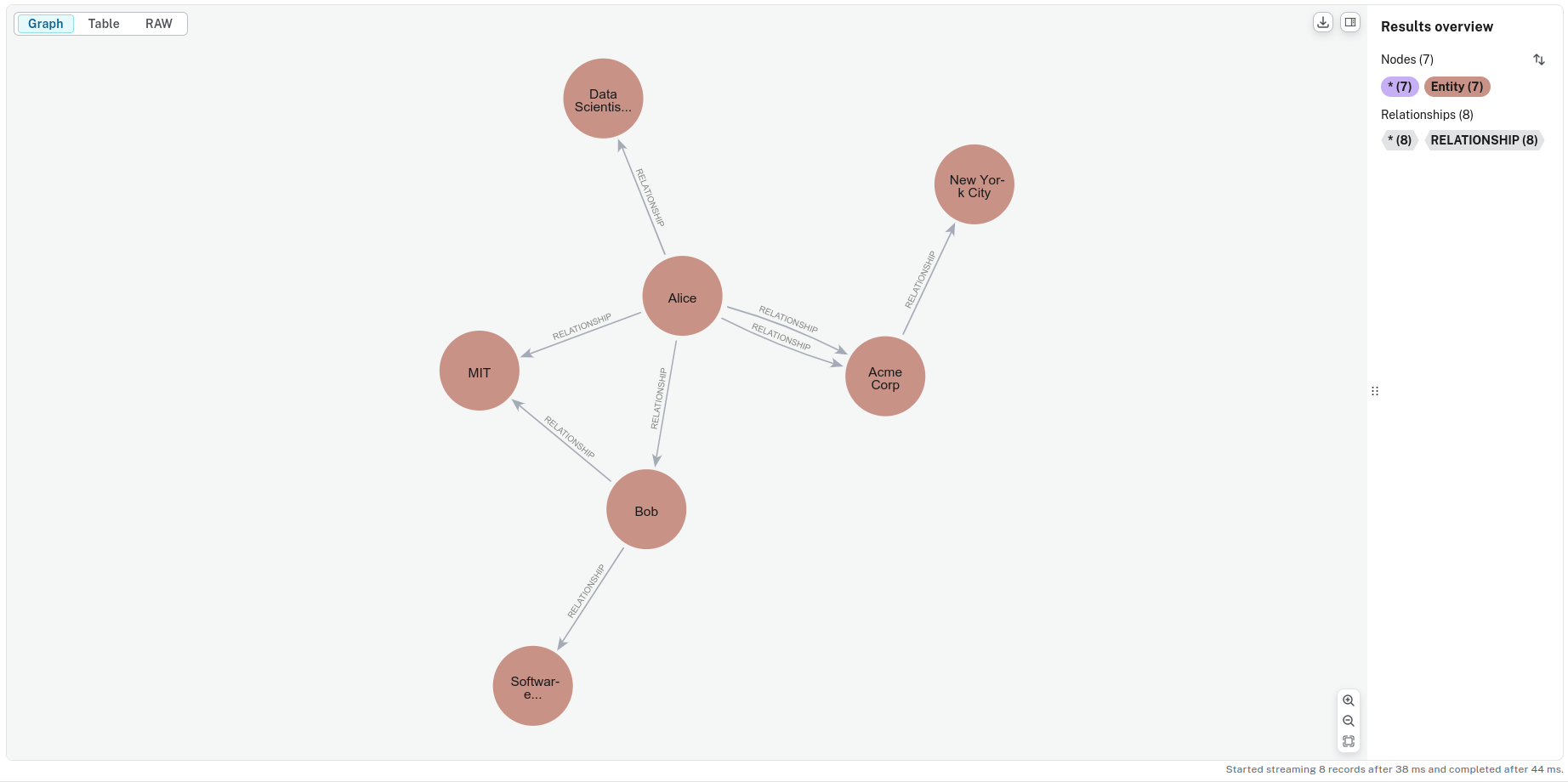
Fig 4: Visualization of the Knowledge Graph
Let’s explore how to map nodes with their IDs and integrate this information, along with vectors, into Qdrant. First, let’s create a Qdrant collection.
Creating Qdrant Collection
You can create a collection once you have set up your Qdrant instance. A collection in Qdrant holds vectors for search and retrieval.
def create_collection(client, collection_name, vector_dimension):
try:
# Try to fetch the collection status
try:
collection_info = client.get_collection(collection_name)
print(f"Skipping creating collection; '{collection_name}' already exists.")
except Exception as e:
# If collection does not exist, an error will be thrown, so we create the collection
if 'Not found: Collection' in str(e):
print(f"Collection '{collection_name}' not found. Creating it now...")
client.create_collection(
collection_name=collection_name,
vectors_config=models.VectorParams(size=vector_dimension, distance=models.Distance.COSINE)
)
print(f"Collection '{collection_name}' created successfully.")
else:
print(f"Error while checking collection: {e}")
- Qdrant Client: The QdrantClient is used to connect to the Qdrant instance.
- Creating Collection: The create_collection function checks if a collection exists. If not, it creates one with a specified vector dimension and distance metric (cosine similarity in this case).
Generating Embeddings
Next, we define a function that generates embeddings for text using OpenAI’s API.
def openai_embeddings(text):
response = client.embeddings.create(
input=text,
model="text-embedding-3-small"
)
return response.data[0].embedding
This function uses OpenAI’s embedding model to transform input text into vector representations.
Ingesting into Qdrant
Let’s ingest the data into the vector database.
def ingest_to_qdrant(collection_name, raw_data, node_id_mapping):
embeddings = [openai_embeddings(paragraph) for paragraph in raw_data.split("\n")]
qdrant_client.upsert(
collection_name=collection_name,
points=[
{
"id": str(uuid.uuid4()),
"vector": embedding,
"payload": {"id": node_id}
}
for node_id, embedding in zip(node_id_mapping.values(), embeddings)
]
)
The ingest_to_qdrant function generates embeddings for each paragraph in the raw data and stores them in a Qdrant collection. It associates each embedding with a unique ID and its corresponding node ID from the node_id_mapping dictionary, ensuring proper linkage for later retrieval.
Retrieval & Generation
In this section, we will create the retrieval and generation engine for the system.
Building a Retriever
The retriever integrates vector search and graph data, enabling semantic similarity searches with Qdrant and fetching relevant graph data from Neo4j. This enriches the RAG process and allows for more informed responses.
def retriever_search(neo4j_driver, qdrant_client, collection_name, query):
retriever = QdrantNeo4jRetriever(
driver=neo4j_driver,
client=qdrant_client,
collection_name=collection_name,
id_property_external="id",
id_property_neo4j="id",
)
results = retriever.search(query_vector=openai_embeddings(query), top_k=5)
return results
The QdrantNeo4jRetriever handles both vector search and graph data fetching, combining Qdrant for vector-based retrieval and Neo4j for graph-based queries.
Vector Search:
qdrant_clientconnects to Qdrant for efficient vector similarity search.collection_namespecifies where vectors are stored.id_property_external="id"maps the external entity’s ID for retrieval.
Graph Fetching:
neo4j_driverconnects to Neo4j for querying graph data.id_property_neo4j="id"ensures the entity IDs from Qdrant match the graph nodes in Neo4j.
Querying Neo4j for Related Graph Data
We need to fetch subgraph data from a Neo4j database based on specific entity IDs after the retriever has provided the relevant IDs.
def fetch_related_graph(neo4j_client, entity_ids):
query = """
MATCH (e:Entity)-[r1]-(n1)-[r2]-(n2)
WHERE e.id IN $entity_ids
RETURN e, r1 as r, n1 as related, r2, n2
UNION
MATCH (e:Entity)-[r]-(related)
WHERE e.id IN $entity_ids
RETURN e, r, related, null as r2, null as n2
"""
with neo4j_client.session() as session:
result = session.run(query, entity_ids=entity_ids)
subgraph = []
for record in result:
subgraph.append({
"entity": record["e"],
"relationship": record["r"],
"related_node": record["related"]
})
if record["r2"] and record["n2"]:
subgraph.append({
"entity": record["related"],
"relationship": record["r2"],
"related_node": record["n2"]
})
return subgraph
The function fetch_related_graph takes in a Neo4j client and a list of entity_ids. It runs a Cypher query to find related nodes (entities) and their relationships based on the given entity IDs. The query matches entities (e:Entity) and finds related nodes through any relationship [r]. The function returns a list of subgraph data, where each record contains the entity, relationship, and related_node.
This subgraph is essential for generating context to answer user queries.
Setting up the Graph Context
The second part of the implementation involves preparing a graph context. We’ll fetch relevant subgraph data from a Neo4j database and format it for the model. Let’s break it down.
def format_graph_context(subgraph):
nodes = set()
edges = []
for entry in subgraph:
entity = entry["entity"]
related = entry["related_node"]
relationship = entry["relationship"]
nodes.add(entity["name"])
nodes.add(related["name"])
edges.append(f"{entity['name']} {relationship['type']} {related['name']}")
return {"nodes": list(nodes), "edges": edges}
The function format_graph_context processes a subgraph returned by a Neo4j query. It extracts the graph’s entities (nodes) and relationships (edges). The nodes set ensures each entity is added only once. The edges list captures the relationships in a readable format: Entity1 relationship Entity2.
Integrating with the LLM
Now that we have the graph context, we need to generate a prompt for a language model like GPT-4. This is where the core of the Retrieval-Augmented Generation (RAG) happens — we combine the graph data and the user query into a comprehensive prompt for the model.
def graphRAG_run(graph_context, user_query):
nodes_str = ", ".join(graph_context["nodes"])
edges_str = "; ".join(graph_context["edges"])
prompt = f"""
You are an intelligent assistant with access to the following knowledge graph:
Nodes: {nodes_str}
Edges: {edges_str}
Using this graph, Answer the following question:
User Query: "{user_query}"
"""
try:
response = client.chat.completions.create(
model="gpt-4",
messages=[
{"role": "system", "content": "Provide the answer for the following question:"},
{"role": "user", "content": prompt}
]
)
return response.choices[0].message
except Exception as e:
return f"Error querying LLM: {str(e)}"
The function graphRAG_run takes the graph context (nodes and edges) and the user query, combining them into a structured prompt for the LLM. The nodes and edges are formatted as readable strings to form part of the LLM input. The LLM is then queried with the generated prompt, asking it to refine the user query using the graph context and provide an answer. If the model successfully generates a response, it returns the answer.
End-to-End Pipeline
Finally, let’s integrate everything into an end-to-end pipeline where we ingest some sample data, run the retrieval process, and query the language model.
if __name__ == "__main__":
print("Script started")
print("Loading environment variables...")
load_dotenv('.env.local')
print("Environment variables loaded")
print("Initializing clients...")
neo4j_driver = GraphDatabase.driver(neo4j_uri, auth=(neo4j_username, neo4j_password))
qdrant_client = QdrantClient(
url=qdrant_url,
api_key=qdrant_key
)
print("Clients initialized")
print("Creating collection...")
collection_name = "graphRAGstoreds"
vector_dimension = 1536
create_collection(qdrant_client, collection_name, vector_dimension)
print("Collection created/verified")
print("Extracting graph components...")
raw_data = """Alice is a data scientist at TechCorp's Seattle office.
Bob and Carol collaborate on the Alpha project.
Carol transferred to the New York office last year.
Dave mentors both Alice and Bob.
TechCorp's headquarters is in Seattle.
Carol leads the East Coast team.
Dave started his career in Seattle.
The Alpha project is managed from New York.
Alice previously worked with Carol at DataCo.
Bob joined the team after Dave's recommendation.
Eve runs the West Coast operations from Seattle.
Frank works with Carol on client relations.
The New York office expanded under Carol's leadership.
Dave's team spans multiple locations.
Alice visits Seattle monthly for team meetings.
Bob's expertise is crucial for the Alpha project.
Carol implemented new processes in New York.
Eve and Dave collaborated on previous projects.
Frank reports to the New York office.
TechCorp's main AI research is in Seattle.
The Alpha project revolutionized East Coast operations.
Dave oversees projects in both offices.
Bob's contributions are mainly remote.
Carol's team grew significantly after moving to New York.
Seattle remains the technology hub for TechCorp."""
nodes, relationships = extract_graph_components(raw_data)
print("Nodes:", nodes)
print("Relationships:", relationships)
print("Ingesting to Neo4j...")
node_id_mapping = ingest_to_neo4j(nodes, relationships)
print("Neo4j ingestion complete")
print("Ingesting to Qdrant...")
ingest_to_qdrant(collection_name, raw_data, node_id_mapping)
print("Qdrant ingestion complete")
query = "How is Bob connected to New York?"
print("Starting retriever search...")
retriever_result = retriever_search(neo4j_driver, qdrant_client, collection_name, query)
print("Retriever results:", retriever_result)
print("Extracting entity IDs...")
entity_ids = [item.content.split("'id': '")[1].split("'")[0] for item in retriever_result.items]
print("Entity IDs:", entity_ids)
print("Fetching related graph...")
subgraph = fetch_related_graph(neo4j_driver, entity_ids)
print("Subgraph:", subgraph)
print("Formatting graph context...")
graph_context = format_graph_context(subgraph)
print("Graph context:", graph_context)
print("Running GraphRAG...")
answer = graphRAG_run(graph_context, query)
print("Final Answer:", answer)
Here’s what’s happening:
- First, the user query is defined (“How is Bob connected to New York?”).
- The QdrantNeo4jRetriever searches for related entities in the Qdrant vector database based on the user query’s embedding. It retrieves the top 5 results (top_k=5).
- The entity_ids are extracted from the retriever result.
- The fetch_related_graph function retrieves related entities and their relationships from the Neo4j database.
- The format_graph_context function prepares the graph data in a format the LLM can understand.
- Finally, the graphRAG_run function is called to generate and query the language model, producing an answer based on the retrieved graph context.
With this, we have successfully created GraphRAG, a system capable of capturing complex relationships and delivering improved performance compared to the baseline RAG approach.
Advantages of Qdrant + Neo4j GraphRAG
Combining Qdrant with Neo4j in a GraphRAG architecture offers several compelling advantages, particularly regarding recall and precision combo, contextual understanding, adaptability to complex queries, and better cost and scalability.
- Improved Recall and Precision: By leveraging Qdrant, a highly efficient vector search engine, alongside Neo4j’s robust graph database, the system benefits from both semantic search and relationship-based retrieval. Qdrant identifies relevant vectors and captures the similarity between queries and stored data. At the same time, Neo4j adds a layer of connectivity through its graph structure, ensuring that relevant and contextually linked information is retrieved. This combination improves recall (retrieving a broader set of relevant results) and precision (delivering more accurate and contextually relevant results), addressing a common challenge in traditional retrieval-based AI systems.
- Enhanced Contextual Understanding: Neo4j enhances contextual understanding by representing information as a graph, where entities and their relationships are naturally modeled. When integrated with Qdrant, the system can retrieve similar items based on vector embeddings and those that fit within the desired relational context, leading to more nuanced and meaningful responses.
- Adaptability to Complex Queries: Combining Qdrant and Neo4j makes the system highly adaptable to complex queries. While Qdrant handles the vector search for relevant data, Neo4j’s graph capabilities enable sophisticated querying through relationships. This allows for multi-hop reasoning and handling complex, structured queries that would be challenging for traditional search engines.
- Better Cost & Scalability: GraphRAG, on its own, demands significant resources, as it relies on LLMs to construct and query knowledge graphs. It also employs clustering algorithms to create semantic clusters for local searches. These can hinder scalability and increase costs. Qdrant addresses the issue of local search through vector search, while Neo4j’s knowledge graph is queried for more precise answers, enhancing both efficiency and accuracy. Furthermore, instead of using an LLM, Named Entity Recognition (NER)-based techniques can reduce the cost further, but it depends mainly on the dataset.
Conclusion
GraphRAG with Neo4j and Qdrant marks an important step forward in retrieval-augmented generation. This hybrid approach delivers significant advantages by combining vector search and graph databases. Qdrant’s semantic search capabilities enhance recall accuracy, while Neo4j’s relationship modeling provides deeper context understanding.
The implementation template we’ve explored offers a foundation for your projects. You can adapt and customize it based on your specific needs, whether for document analysis, knowledge management, or other information retrieval tasks.
As AI systems evolve, this combination of technologies shows how we can build smarter, more efficient solutions. We encourage you to experiment with this approach and discover how it can enhance your applications.