Chat With Product PDF Manuals Using Hybrid Search
| Time: 120 min | Level: Advanced | Output: GitHub |
|---|
With the proliferation of digital manuals and the increasing demand for quick and accurate customer support, having a chatbot capable of efficiently parsing through complex PDF documents and delivering precise information can be a game-changer for any business.
In this tutorial, we’ll walk you through the process of building a RAG-based chatbot, designed specifically to assist users with understanding the operation of various household appliances. We’ll cover the essential steps required to build your system, including data ingestion, natural language understanding, and response generation for customer support use cases.
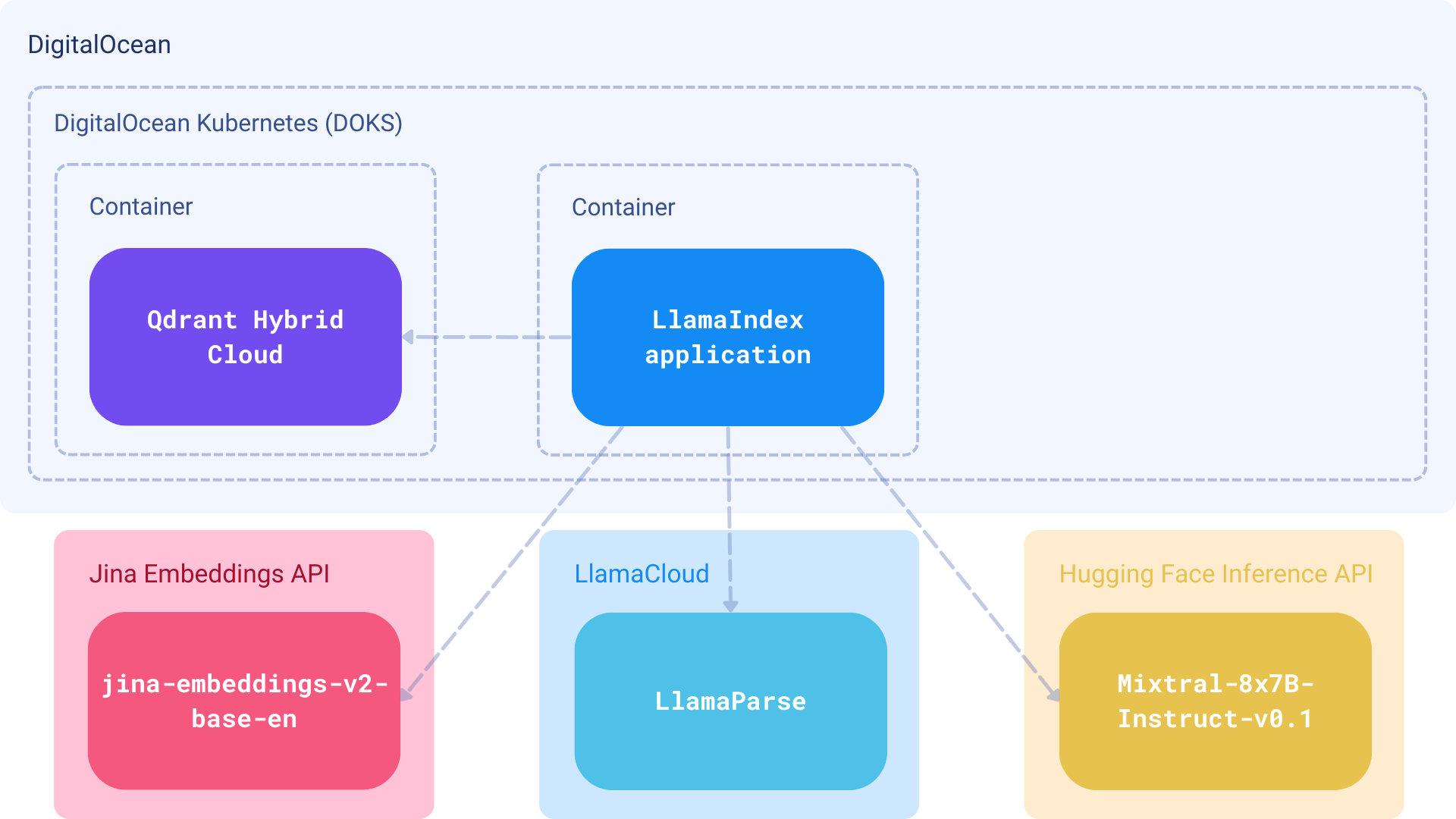
Components
- Embeddings: Jina Embeddings, served via the Jina Embeddings API
- Database: Qdrant Hybrid Cloud, deployed in a managed Kubernetes cluster on DigitalOcean (DOKS)
- LLM: Mixtral-8x7B-Instruct-v0.1 language model on HuggingFace
- Framework: LlamaIndex for extended RAG functionality and Hybrid Search support.
- Parser: LlamaParse as a way to parse complex documents with embedded objects such as tables and figures.
Procedure
Retrieval Augmented Generation (RAG) combines search with language generation. An external information retrieval system is used to identify documents likely to provide information relevant to the user’s query. These documents, along with the user’s request, are then passed on to a text-generating language model, producing a natural response.
This method enables a language model to respond to questions and access information from a much larger set of documents than it could see otherwise. The language model only looks at a few relevant sections of the documents when generating responses, which also helps to reduce inexplicable errors.
Service Managed Kubernetes, powered by OVH Public Cloud Instances, a leading European cloud provider. With OVHcloud Load Balancers and disks built in. OVHcloud Managed Kubernetes provides high availability, compliance, and CNCF conformance, allowing you to focus on your containerized software layers with total reversibility.
Prerequisites
Deploying Qdrant Hybrid Cloud on DigitalOcean
DigitalOcean Kubernetes (DOKS) is a managed Kubernetes service that lets you deploy Kubernetes clusters without the complexities of handling the control plane and containerized infrastructure. Clusters are compatible with standard Kubernetes toolchains and integrate natively with DigitalOcean Load Balancers and volumes.
- To start using managed Kubernetes on DigitalOcean, follow the platform-specific documentation.
- Once your Kubernetes clusters are up, you can begin deploying Qdrant Hybrid Cloud.
- Once it’s deployed, you should have a running Qdrant cluster with an API key.
Development environment
Then, install all dependencies:
!pip install -U \
llama-index \
llama-parse \
python-dotenv \
llama-index-embeddings-jinaai \
llama-index-llms-huggingface \
llama-index-vector-stores-qdrant \
"huggingface_hub[inference]" \
datasets
Set up secret key values on .env file:
JINAAI_API_KEY
HF_INFERENCE_API_KEY
LLAMA_CLOUD_API_KEY
QDRANT_HOST
QDRANT_API_KEY
Load all environment variables:
import os
from dotenv import load_dotenv
load_dotenv('./.env')
Implementation
Connect Jina Embeddings and Mixtral LLM
LlamaIndex provides built-in support for the Jina Embeddings API. To use it, you need to initialize the JinaEmbedding object with your API Key and model name.
For the LLM, you need to wrap it in a subclass of llama_index.llms.CustomLLM to make it compatible with LlamaIndex.
# connect embeddings
from llama_index.embeddings.jinaai import JinaEmbedding
jina_embedding_model = JinaEmbedding(
model="jina-embeddings-v2-base-en",
api_key=os.getenv("JINAAI_API_KEY"),
)
# connect LLM
from llama_index.llms.huggingface import HuggingFaceInferenceAPI
mixtral_llm = HuggingFaceInferenceAPI(
model_name = "mistralai/Mixtral-8x7B-Instruct-v0.1",
token=os.getenv("HF_INFERENCE_API_KEY"),
)
Prepare data for RAG
This example will use household appliance manuals, which are generally available as PDF documents.
LlamaPar
In the data folder, we have three documents, and we will use it to extract the textual content from the PDF and use it as a knowledge base in a simple RAG.
The free LlamaIndex Cloud plan is sufficient for our example:
import nest_asyncio
nest_asyncio.apply()
from llama_parse import LlamaParse
llamaparse_api_key = os.getenv("LLAMA_CLOUD_API_KEY")
llama_parse_documents = LlamaParse(api_key=llamaparse_api_key, result_type="markdown").load_data([
"data/DJ68-00682F_0.0.pdf",
"data/F500E_WF80F5E_03445F_EN.pdf",
"data/O_ME4000R_ME19R7041FS_AA_EN.pdf"
])
Store data into Qdrant
The code below does the following:
- create a vector store with Qdrant client;
- get an embedding for each chunk using Jina Embeddings API;
- combines
sparseanddensevectors for hybrid search; - stores all data into Qdrant;
Hybrid search with Qdrant must be enabled from the beginning - we can simply set enable_hybrid=True.
# By default llamaindex uses OpenAI models
# setting embed_model to Jina and llm model to Mixtral
from llama_index.core import Settings
Settings.embed_model = jina_embedding_model
Settings.llm = mixtral_llm
from llama_index.core import VectorStoreIndex, StorageContext
from llama_index.vector_stores.qdrant import QdrantVectorStore
import qdrant_client
client = qdrant_client.QdrantClient(
url=os.getenv("QDRANT_HOST"),
api_key=os.getenv("QDRANT_API_KEY")
)
vector_store = QdrantVectorStore(
client=client, collection_name="demo", enable_hybrid=True, batch_size=20
)
Settings.chunk_size = 512
storage_context = StorageContext.from_defaults(vector_store=vector_store)
index = VectorStoreIndex.from_documents(
documents=llama_parse_documents,
storage_context=storage_context
)
Prepare a prompt
Here we will create a custom prompt template. This prompt asks the LLM to use only the context information retrieved from Qdrant. When querying with hybrid mode, we can set similarity_top_k and sparse_top_k separately:
sparse_top_krepresents how many nodes will be retrieved from each dense and sparse query.similarity_top_kcontrols the final number of returned nodes. In the above setting, we end up with 10 nodes.
Then, we assemble the query engine using the prompt.
from llama_index.core import PromptTemplate
qa_prompt_tmpl = (
"Context information is below.\n"
"-------------------------------"
"{context_str}\n"
"-------------------------------"
"Given the context information and not prior knowledge,"
"answer the query. Please be concise, and complete.\n"
"If the context does not contain an answer to the query,"
"respond with \"I don't know!\"."
"Query: {query_str}\n"
"Answer: "
)
qa_prompt = PromptTemplate(qa_prompt_tmpl)
from llama_index.core.retrievers import VectorIndexRetriever
from llama_index.core.query_engine import RetrieverQueryEngine
from llama_index.core import get_response_synthesizer
from llama_index.core import Settings
Settings.embed_model = jina_embedding_model
Settings.llm = mixtral_llm
# retriever
retriever = VectorIndexRetriever(
index=index,
similarity_top_k=2,
sparse_top_k=12,
vector_store_query_mode="hybrid"
)
# response synthesizer
response_synthesizer = get_response_synthesizer(
llm=mixtral_llm,
text_qa_template=qa_prompt,
response_mode="compact",
)
# query engine
query_engine = RetrieverQueryEngine(
retriever=retriever,
response_synthesizer=response_synthesizer,
)
Run a test query
Now you can ask questions and receive answers based on the data:
Question
result = query_engine.query("What temperature should I use for my laundry?")
print(result.response)
Answer
The water temperature is set to 70 ˚C during the Eco Drum Clean cycle. You cannot change the water temperature. However, the temperature for other cycles is not specified in the context.
And that’s it! Feel free to scale this up to as many documents and complex PDFs as you like.