Movie Recommendation System
| Time: 120 min | Level: Advanced | Output: GitHub |
|---|
In this tutorial, you will build a mechanism that recommends movies based on defined preferences. Vector databases like Qdrant are good for storing high-dimensional data, such as user and item embeddings. They can enable personalized recommendations by quickly retrieving similar entries based on advanced indexing techniques. In this specific case, we will use sparse vectors to create an efficient and accurate recommendation system.
Privacy and Sovereignty: Since preference data is proprietary, it should be stored in a secure and controlled environment. Our vector database can easily be hosted on OVHcloud, our trusted Qdrant Hybrid Cloud partner. This means that Qdrant can be run from your OVHcloud region, but the database itself can still be managed from within Qdrant Cloud’s interface. Both products have been tested for compatibility and scalability, and we recommend their managed Kubernetes service.
To see the entire output, use our notebook with complete instructions.
Components
- Dataset: The MovieLens dataset contains a list of movies and ratings given by users.
- Cloud: OVHcloud, with managed Kubernetes.
- Vector DB: Qdrant Hybrid Cloud running on OVHcloud.
Methodology: We’re adopting a collaborative filtering approach to construct a recommendation system from the dataset provided. Collaborative filtering works on the premise that if two users share similar tastes, they’re likely to enjoy similar movies. Leveraging this concept, we’ll identify users whose ratings align closely with ours, and explore the movies they liked but we haven’t seen yet. To do this, we’ll represent each user’s ratings as a vector in a high-dimensional, sparse space. Using Qdrant, we’ll index these vectors and search for users whose ratings vectors closely match ours. Ultimately, we will see which movies were enjoyed by users similar to us.
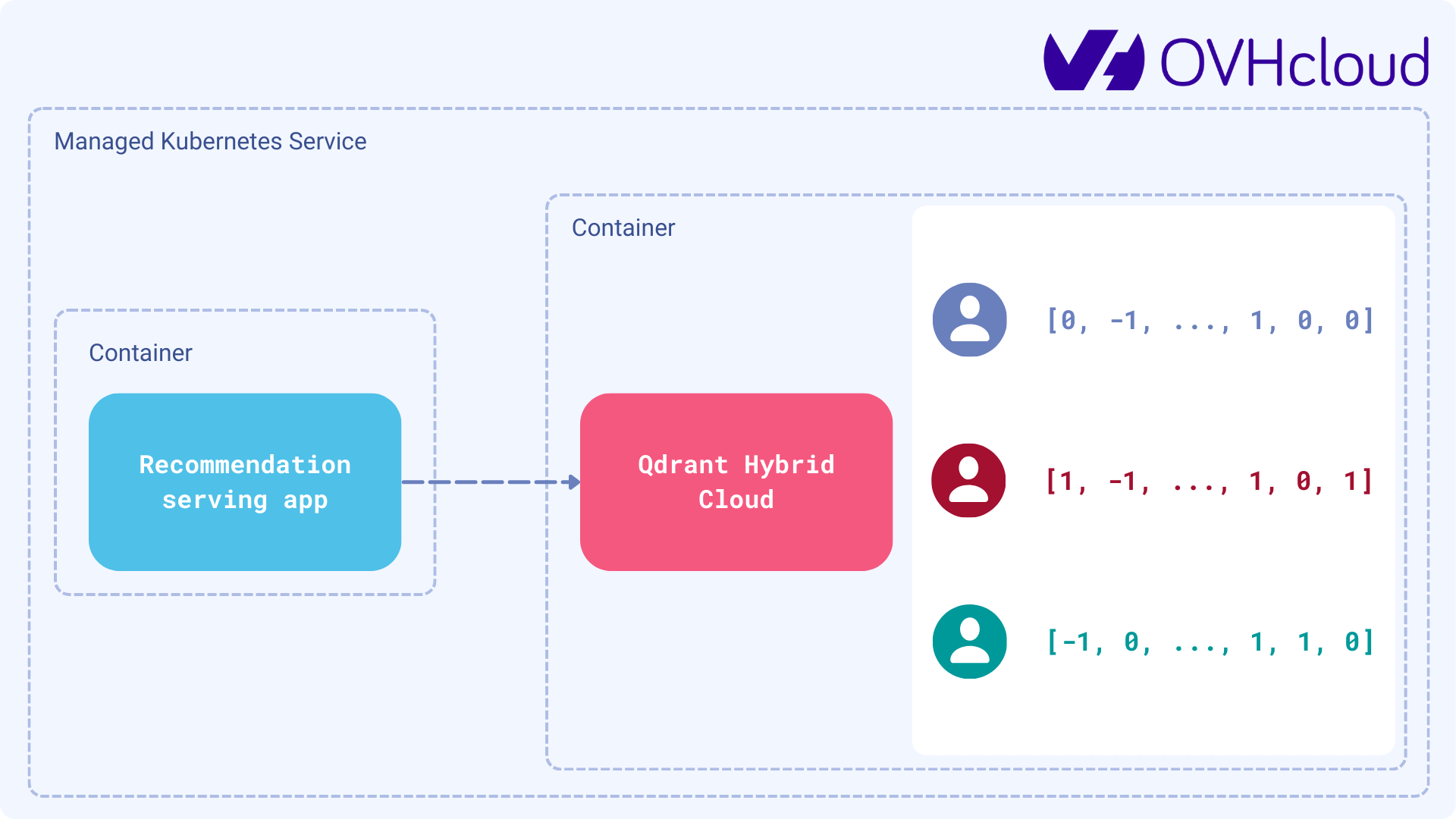
Deploying Qdrant Hybrid Cloud on OVHcloud
Service Managed Kubernetes, powered by OVH Public Cloud Instances, a leading European cloud provider. With OVHcloud Load Balancers and disks built in. OVHcloud Managed Kubernetes provides high availability, compliance, and CNCF conformance, allowing you to focus on your containerized software layers with total reversibility.
- To start using managed Kubernetes on OVHcloud, follow the platform-specific documentation.
- Once your Kubernetes clusters are up, you can begin deploying Qdrant Hybrid Cloud.
Prerequisites
Download and unzip the MovieLens dataset:
mkdir -p data
wget https://files.grouplens.org/datasets/movielens/ml-1m.zip
unzip ml-1m.zip -d data
The necessary * libraries are installed using pip, including pandas for data manipulation, qdrant-client for interfacing with Qdrant, and *-dotenv for managing environment variables.
!pip install -U \
pandas \
qdrant-client \
*-dotenv
The .env file is used to store sensitive information like the Qdrant host URL and API key securely.
QDRANT_HOST
QDRANT_API_KEY
Load all environment variables into the setup:
import os
from dotenv import load_dotenv
load_dotenv('./.env')
Implementation
Load the data from the MovieLens dataset into pandas DataFrames to facilitate data manipulation and analysis.
from qdrant_client import QdrantClient, models
import pandas as pd
Load user data:
users = pd.read_csv(
'data/ml-1m/users.dat',
sep='::',
names=['user_id', 'gender', 'age', 'occupation', 'zip'],
engine='*'
)
users.head()
Add movies:
movies = pd.read_csv(
'data/ml-1m/movies.dat',
sep='::',
names=['movie_id', 'title', 'genres'],
engine='*',
encoding='latin-1'
)
movies.head()
Finally, add the ratings:
ratings = pd.read_csv(
'data/ml-1m/ratings.dat',
sep='::',
names=['user_id', 'movie_id', 'rating', 'timestamp'],
engine='*'
)
ratings.head()
Normalize the ratings
Sparse vectors can use advantage of negative values, so we can normalize ratings to have a mean of 0 and a standard deviation of 1. This normalization ensures that ratings are consistent and centered around zero, enabling accurate similarity calculations. In this scenario we can take into account movies that we don’t like.
ratings.rating = (ratings.rating - ratings.rating.mean()) / ratings.rating.std()
To get the results:
ratings.head()
Data preparation
Now you will transform user ratings into sparse vectors, where each vector represents ratings for different movies. This step prepares the data for indexing in Qdrant.
First, create a collection with configured sparse vectors. For sparse vectors, you don’t need to specify the dimension, because it’s extracted from the data automatically.
from collections import defaultdict
user_sparse_vectors = defaultdict(lambda: {"values": [], "indices": []})
for row in ratings.itertuples():
user_sparse_vectors[row.user_id]["values"].append(row.rating)
user_sparse_vectors[row.user_id]["indices"].append(row.movie_id)
Connect to Qdrant and create a collection called movielens:
client = QdrantClient(
url = os.getenv("QDRANT_HOST"),
api_key = os.getenv("QDRANT_API_KEY")
)
client.create_collection(
"movielens",
vectors_config={},
sparse_vectors_config={
"ratings": models.SparseVectorParams()
}
)
Upload user ratings to the movielens collection in Qdrant as sparse vectors, along with user metadata. This step populates the database with the necessary data for recommendation generation.
def data_generator():
for user in users.itertuples():
yield models.PointStruct(
id=user.user_id,
vector={
"ratings": user_sparse_vectors[user.user_id]
},
payload=user._asdict()
)
client.upload_points(
"movielens",
data_generator()
)
Recommendations
Personal movie ratings are specified, where positive ratings indicate likes and negative ratings indicate dislikes. These ratings serve as the basis for finding similar users with comparable tastes.
Personal ratings are converted into a sparse vector representation suitable for querying Qdrant. This vector represents the user’s preferences across different movies.
Let’s try to recommend something for ourselves:
1 = Like
-1 = dislike
# Search with movies[movies.title.str.contains("Matrix", case=False)].
my_ratings = {
2571: 1, # Matrix
329: 1, # Star Trek
260: 1, # Star Wars
2288: -1, # The Thing
1: 1, # Toy Story
1721: -1, # Titanic
296: -1, # Pulp Fiction
356: 1, # Forrest Gump
2116: 1, # Lord of the Rings
1291: -1, # Indiana Jones
1036: -1 # Die Hard
}
inverse_ratings = {k: -v for k, v in my_ratings.items()}
def to_vector(ratings):
vector = models.SparseVector(
values=[],
indices=[]
)
for movie_id, rating in ratings.items():
vector.values.append(rating)
vector.indices.append(movie_id)
return vector
Query Qdrant to find users with similar tastes based on the provided personal ratings. The search returns a list of similar users along with their ratings, facilitating collaborative filtering.
results = client.query_points(
"movielens",
query=to_vector(my_ratings),
using="ratings",
with_vectors=True, # We will use those to find new movies
limit=20
).points
Movie scores are computed based on how frequently each movie appears in the ratings of similar users, weighted by their ratings. This step identifies popular movies among users with similar tastes. Calculate how frequently each movie is found in similar users’ ratings
def results_to_scores(results):
movie_scores = defaultdict(lambda: 0)
for user in results:
user_scores = user.vector['ratings']
for idx, rating in zip(user_scores.indices, user_scores.values):
if idx in my_ratings:
continue
movie_scores[idx] += rating
return movie_scores
The top-rated movies are sorted based on their scores and printed as recommendations for the user. These recommendations are tailored to the user’s preferences and aligned with their tastes. Sort movies by score and print top five:
movie_scores = results_to_scores(results)
top_movies = sorted(movie_scores.items(), key=lambda x: x[1], reverse=True)
for movie_id, score in top_movies[:5]:
print(movies[movies.movie_id == movie_id].title.values[0], score)
Result:
Star Wars: Episode V - The Empire Strikes Back (1980) 20.02387858
Star Wars: Episode VI - Return of the Jedi (1983) 16.443184379999998
Princess Bride, The (1987) 15.840068229999996
Raiders of the Lost Ark (1981) 14.94489462
Sixth Sense, The (1999) 14.570322149999999