Video Anomaly Detection: Edge-to-Cloud Pipeline
| Time: 90 min | Level: Advanced | Output: GitHub |
|---|
This is Part 2 of a 3-part series on building real-time video anomaly detection from edge to cloud.
Series:
- Part 1 | Architecture, Twelve Labs, and NVIDIA VSS
- Part 2 | Edge-to-Cloud Pipeline (here)
- Part 3 | Scoring, Governance, and Deployment
In Part 1, we set up the project, covered why kNN anomaly detection in Qdrant outperforms classifiers, integrated Twelve Labs for video embeddings and Q&A, and connected NVIDIA VSS. Now we build the edge.
Why Qdrant Edge
The cloud tier runs a full Qdrant cluster. The edge tier cannot. NVIDIA Jetson devices have limited memory, no guaranteed internet connectivity, and need sub-millisecond kNN lookups without the overhead of a client-server architecture.
Qdrant Edge solves this. It is a lightweight, embedded vector search engine that runs inside your application process. No separate server, no network hops, no Docker container. You get native Rust performance through Python bindings via the qdrant-edge-py package.
The key capabilities we use:
EdgeShard: A self-contained storage unit that manages vector and payload storage and performs local search independently.- Snapshot sync: Download an HNSW-indexed shard from the cloud server and unpack it locally with
EdgeShard.unpack_snapshot(). Partial snapshots keep the edge updated incrementally. - Offline operation: Edge shards work without any network connectivity. Data queued locally gets synced when the connection returns.
Install the package:
pip install qdrant-edge-py
Two-Shard Edge Architecture
This is the technical heart of the system. Edge devices need to serve kNN queries with minimal latency while continuously ingesting new clips.
Why can’t we just run a single shard on the edge? Two reasons: (1) Building an HNSW index is expensive and blocks reads, and (2) you can’t ship the entire cloud baseline to every edge device since it may contain hundreds of thousands of vectors.
The Solution: Mutable + Immutable Shards
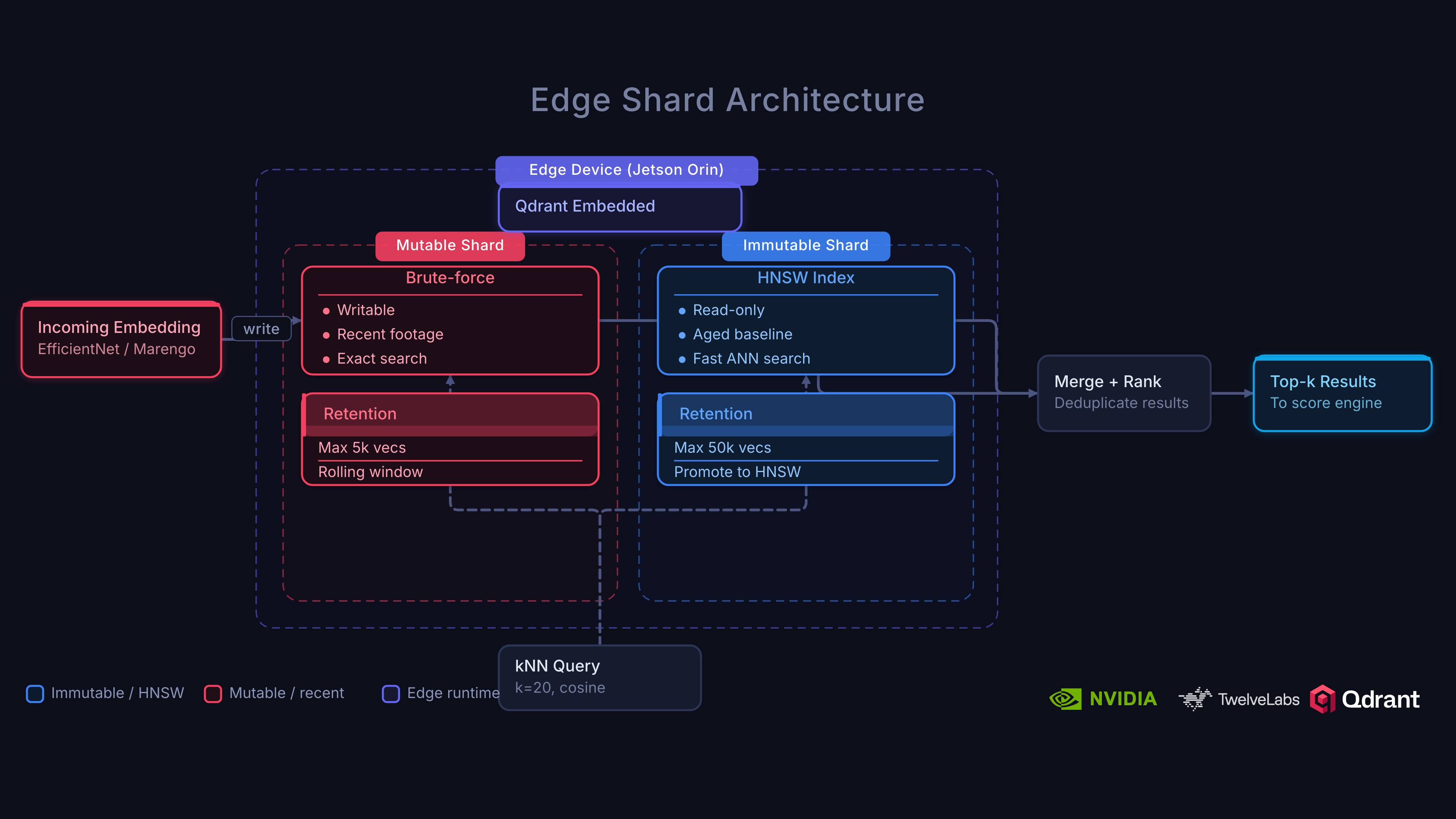
The edge collection uses two EdgeShard instances:
Immutable shard. A pre-built HNSW index synced from the cloud via snapshot. Contains a representative subset of the normal baseline selected via k-means clustering (default: 500 centroids). This shard is read-only. It provides the core “what does normal look like?” reference.
Mutable shard. Receives live clip embeddings as they arrive. Unindexed (brute-force scan), optimized for fast writes. Contains recent clips from this specific camera site, capturing local context the cloud baseline may not include.
/edge/detector.py
from qdrant_edge import (
Distance as EdgeDistance,
EdgeConfig,
EdgeShard,
FieldCondition,
Filter,
Point,
Query,
RangeFloat,
SearchRequest,
UpdateOperation,
VectorDataConfig,
)
SHARD_CONFIG = EdgeConfig(
vector_data=VectorDataConfig(
size=EDGE_EMBEDDING_DIM,
distance=EdgeDistance.Cosine,
)
)
class EdgeDetector:
def __init__(self):
self._data_dir = Path(QDRANT_EDGE_PATH)
self._mutable_dir = self._data_dir / "mutable"
self._immutable_dir = self._data_dir / "immutable"
self._mutable_dir.mkdir(parents=True, exist_ok=True)
# Mutable shard: created fresh with config
self._mutable_shard = EdgeShard(str(self._mutable_dir), SHARD_CONFIG)
# Immutable shard: loaded from snapshot (None until first sync)
self._immutable_shard: Optional[EdgeShard] = None
if self._immutable_dir.exists():
self._immutable_shard = EdgeShard(str(self._immutable_dir), None)
Note the asymmetry: the mutable shard is created with a config (it needs to know vector dimensions and distance). The immutable shard is opened with None because its config was baked in when the snapshot was created on the server.
Query Path
Every kNN query searches both shards simultaneously, merges results by score, and takes the top-k:
def score_local(self, embedding: np.ndarray) -> float:
req = SearchRequest(
query=Query.Nearest(embedding.tolist()),
limit=K_NEIGHBORS,
with_payload=False,
)
results = list(self._mutable_shard.search(req))
if self._immutable_shard:
results.extend(self._immutable_shard.search(req))
# Merge and take top-k by score (descending = most similar)
results.sort(key=lambda x: x.score, reverse=True)
top_k = results[:K_NEIGHBORS]
if not top_k:
# No baseline yet: treat as maximally anomalous, not normal
return 1.0
sims = [r.score for r in top_k]
return 1.0 - float(np.mean(sims))
This gives the edge device the best of both worlds: a high-quality global baseline (immutable shard) augmented with recent local context (mutable shard).
Representative Subset Selection
The cloud baseline may contain 100,000+ normal vectors. The edge device only needs 500. We use MiniBatchKMeans to cluster the cloud embeddings and select the vector closest to each centroid:
from sklearn.cluster import MiniBatchKMeans
kmeans = MiniBatchKMeans(n_clusters=500, batch_size=1000)
kmeans.fit(all_embeddings)
# For each cluster, find the embedding closest to the centroid
for i in range(500):
cluster_mask = kmeans.labels_ == i
cluster_embeddings = all_embeddings[cluster_mask]
distances = np.linalg.norm(
cluster_embeddings - kmeans.cluster_centers_[i], axis=1
)
representative_idx = np.argmin(distances)
# Add this embedding to the edge collection
This preserves the baseline’s coverage while fitting comfortably in edge device memory.
When EDGE_SNAPSHOT_KMEANS=500 is set, the backend’s /api/snapshots/full endpoint runs MiniBatchKMeans on the cloud baseline before creating the snapshot, producing a 500-vector representative subset for the edge immutable shard.
Edge Triage: Why Imperfect Is the Point
Processing every frame in the cloud is not only difficult (limited bandwidth, high latency) but also costly. Let’s prove it with some simple math.
How much would it cost to process 24 hours of continuous surveillance through the full cloud pipeline?
At 10-second clips, that’s 8,640 clips per day per camera. Running each through Twelve Labs Marengo embedding + Qdrant scoring + VLM captioning adds up quickly. For a fleet of 50 cameras, you’re looking at 432,000 cloud API calls per day.
So how do we solve this? The answer lies in edge triage.
The edge embedding model (running as a DeepStream inference plugin on Jetson) produces lightweight spatial embeddings with roughly ~0.85 AUC-ROC compared to the cloud’s 0.97. That is a significant accuracy gap. Edge embeddings capture spatial features but miss temporal dynamics entirely.
This is fine, because the edge is not trying to detect anomalies. It is trying to not miss them. The edge threshold (0.06) is set deliberately loose, optimizing for recall over precision:
- Without edge triage: Stream 100% of footage to the cloud. 360 clips/hour/camera through the full pipeline.
- With edge triage: Stream ~15% of footage. ~54 clips/hour/camera. A ~6x bandwidth reduction.
- Cost of false positives: A false escalation costs one cloud API call. The cloud re-scores it, gets a low score, and drops it. No incident created.
- Cost of false negatives: A missed anomaly never reaches the cloud. At ~95% edge recall, roughly 1 in 20 anomalies is missed entirely.
The two-tier architecture only works because the edge is imperfect and the cloud cleans up after it. If the edge were perfect, you wouldn’t need the cloud. If the edge were random, you wouldn’t save any bandwidth. The sweet spot is a cheap, fast model with high recall and tolerable precision.
Edge-to-Cloud Escalation
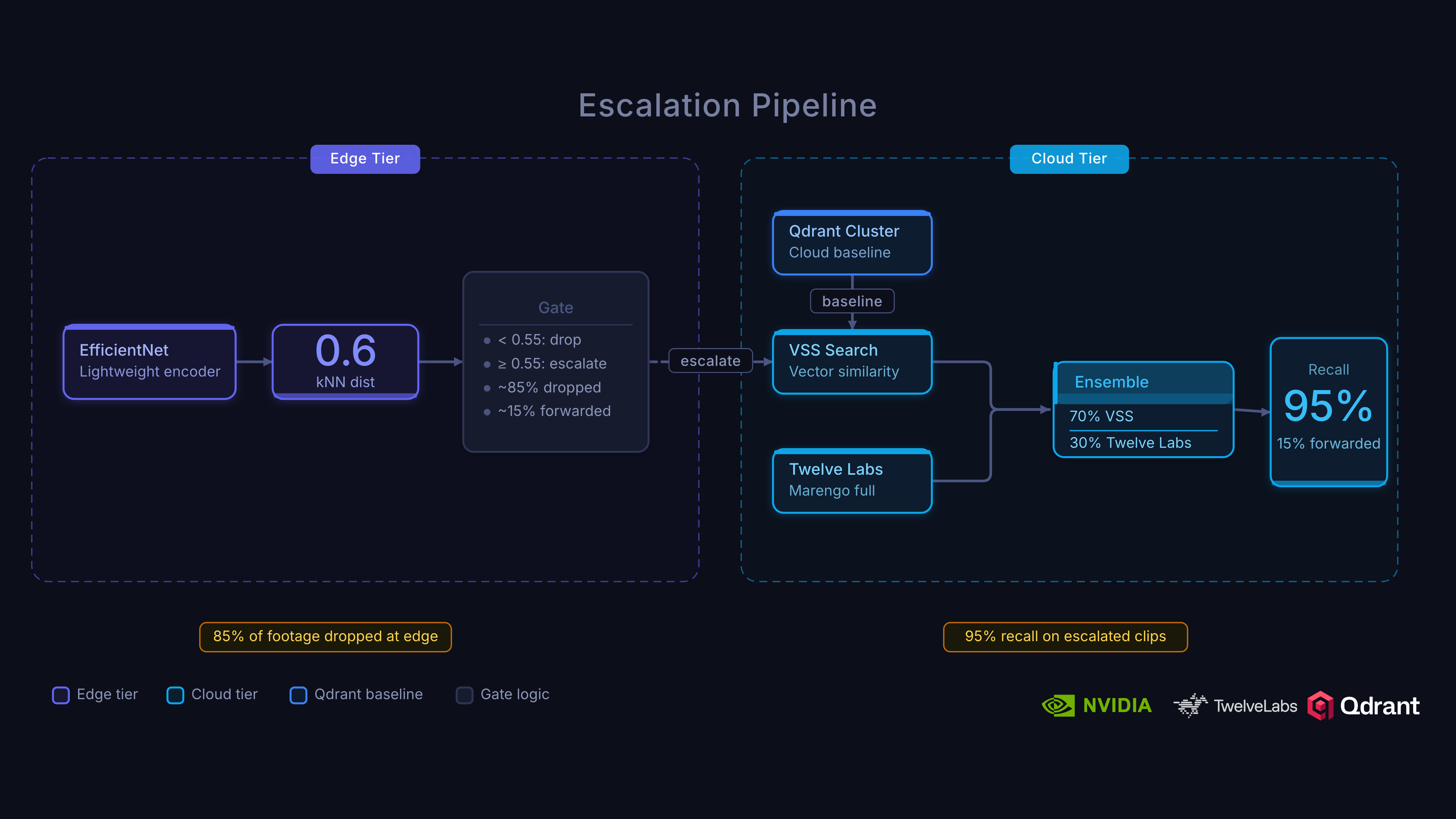
When an edge device scores a clip above the escalation threshold, it sends the clip to the cloud for re-analysis. Here’s where Twelve Labs and Qdrant work together for the final verdict.
Escalation Flow
- Edge detection: DeepStream inference produces an embedding, Qdrant Edge kNN scores above
ESCALATION_THRESHOLD(0.06) - Queue: Metropolis IoT Gateway queues the clip for secure cloud transport (persists across restarts)
- Upload: Clip and edge metadata sent to cloud
- Cloud re-analysis: Twelve Labs Marengo produces embeddings, kNN score in Qdrant Cloud + semantic signals
- VSS enrichment: VLM captioning, audio transcription, CV pipeline (if enabled)
- Ensemble scoring: 70% cloud score + 30% edge score with temporal boost
- Confirmation: Ensemble score compared against threshold (0.038)
The escalation handler in our backend supports both Twelve Labs and local model server paths:
/backend/escalation.py
async def handle_escalation(request: EscalationRequest) -> EscalationResult:
cloud_embedding = None
if request.clip_data:
# Try Twelve Labs path first if enabled
if twelvelabs_client.is_enabled():
try:
# Upload to Twelve Labs for indexing
upload_result = twelvelabs_client.upload_video(
tmp_path, index_type="marengo"
)
video_id = upload_result.get("marengo_video_id")
if video_id:
# Also ingest via VSS if enabled
if vss.is_enabled():
await vss.ingest_video(tmp_path)
# Get cloud embedding from Twelve Labs
embedding = twelvelabs_client.get_video_embedding(video_id)
if embedding:
cloud_embedding = embedding
except Exception:
pass # Fall back to local model server
# Fallback: local model server
if cloud_embedding is None:
async with httpx.AsyncClient(timeout=30.0) as client:
resp = await client.post(
f"{MODEL_SERVER_URL}/embed",
files={"file": (request.clip_filename, request.clip_data)},
)
cloud_embedding = resp.json()["embedding"]
# Score with cloud embedding against Qdrant baseline
scoring_embedding = cloud_embedding or request.edge_embedding
cloud_result = score_clip(
embedding=scoring_embedding,
collection_name=CLOUD_COLLECTION,
k=CONFIRMATION_K,
)
# Return cloud score — confirmation happens after ensemble in the endpoint
cloud_score = cloud_result.anomaly_score
return EscalationResult(
cloud_score=cloud_score,
...
)
Ensemble Scoring
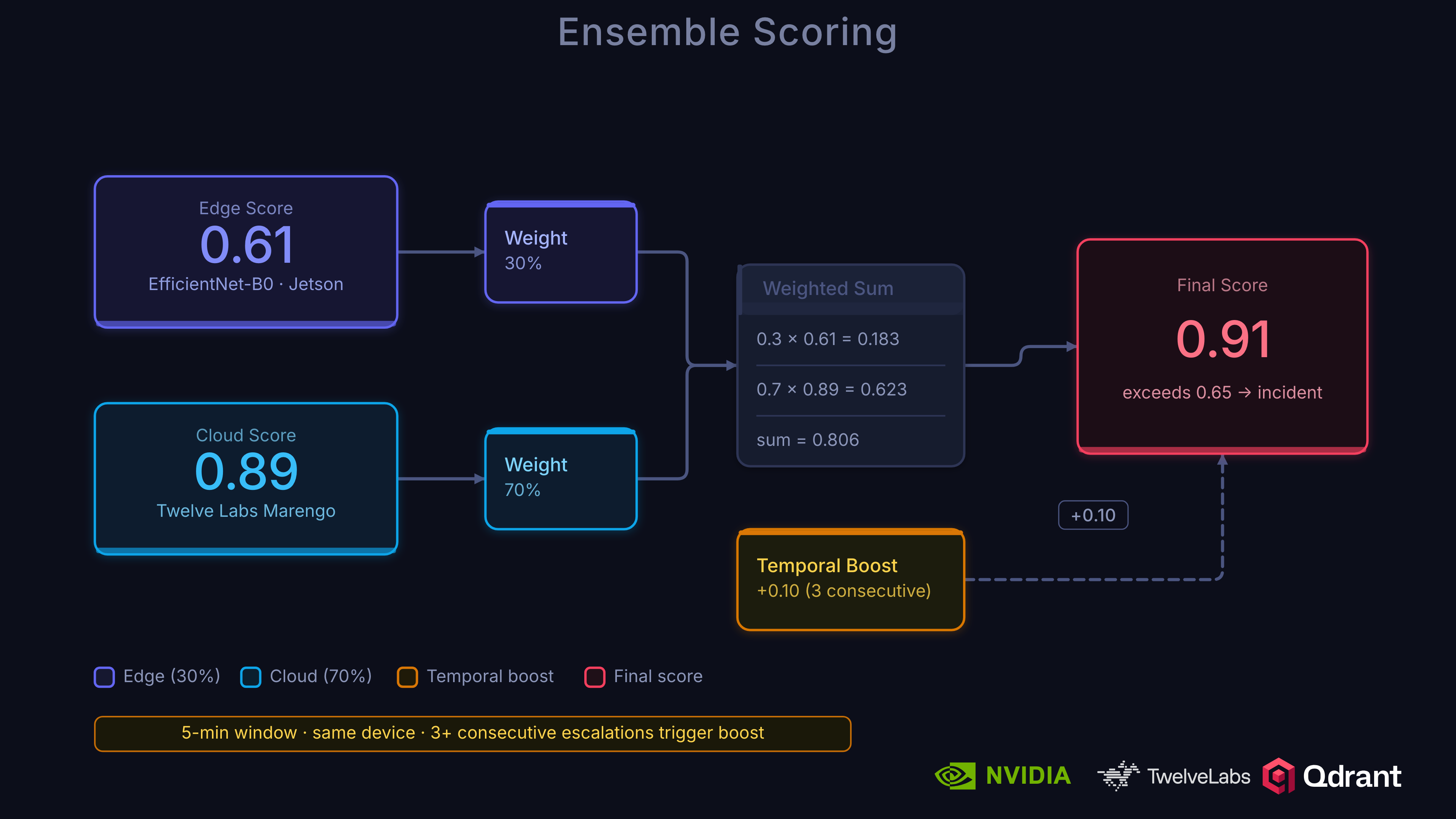
The ensemble weighting reflects the accuracy differential between tiers:
ens = ensemble_scorer.score(
edge_score=edge_score,
cloud_score=cloud_score,
device_id=edge_device_id,
timestamp=time.time(),
)
# Confirmation uses ensemble score, not raw cloud score
is_confirmed = ens.is_anomaly # ensemble_score > threshold (0.038)
A low cloud score suppresses a high edge score (false positive). A high cloud score confirms a high edge score (true anomaly). The threshold (0.038) is lower than the edge threshold (0.06) because the cloud model is more accurate and can set a tighter decision boundary.
Temporal Boosting
Consecutive escalations from the same device within a 5-minute window receive a score boost:
boost = min(0.3, (consecutive_count - 1) * TEMPORAL_BOOST_FACTOR) # Factor = 0.1
final_score = ensemble_score + boost
Three consecutive escalations add +0.2 to the score. This helps sustained events (like an ongoing altercation) cross the confirmation threshold even if individual clip scores are borderline.
Storing Clips Locally
When the edge processes a clip, it stores the embedding in the mutable shard and queues it for cloud sync:
def store_clip(self, embedding: np.ndarray, metadata: dict | None = None) -> str:
clip_id = uuid.uuid4().hex
vector = embedding.tolist()
payload = metadata or {}
payload["sync_timestamp"] = time.time()
self._mutable_shard.update(
UpdateOperation.upsert_points(
[Point(id=clip_id, vector=vector, payload=payload)]
)
)
# Queue for async cloud sync
self._upload_queue.put({"id": clip_id, "vector": vector, "payload": payload})
return clip_id
Snapshot Sync from Cloud
The immutable shard stays current through snapshot syncing. A full sync downloads the entire indexed shard; incremental syncs use partial snapshots that only transfer changed segments:
def sync_from_server(self, full: bool = False) -> None:
# Flush pending uploads first; track whether they succeeded
upload_ok = self._upload_batch(pending_items) # returns True on success
if full or not self._immutable_shard:
# Full sync: download complete snapshot
resp = requests.post(f"{CLOUD_API_URL}/api/snapshots/full", stream=True)
with open(snapshot_path, "wb") as f:
for chunk in resp.iter_content(chunk_size=8192):
f.write(chunk)
EdgeShard.unpack_snapshot(str(snapshot_path), str(self._immutable_dir))
self._immutable_shard = EdgeShard(str(self._immutable_dir), None)
else:
# Incremental: send current manifest, get only changed segments
manifest = self._immutable_shard.snapshot_manifest()
resp = requests.post(
f"{CLOUD_API_URL}/api/snapshots/partial",
json={"manifest": manifest}, stream=True,
)
with open(snapshot_path, "wb") as f:
for chunk in resp.iter_content(chunk_size=8192):
f.write(chunk)
self._immutable_shard.update_from_snapshot(str(snapshot_path))
# Only purge mutable shard if upload succeeded.
# If upload failed, points are not in the cloud yet -- deleting them would cause data loss.
if upload_ok:
self._mutable_shard.update(
UpdateOperation.delete_points_by_filter(
Filter(must=[FieldCondition(
key="sync_timestamp",
range=RangeFloat(lte=sync_timestamp),
)])
)
)
After syncing, points that were already uploaded to the cloud are purged from the mutable shard to prevent double-counting during kNN queries. The cleanup is gated on upload_ok to avoid deleting local data that never reached the cloud.
Offline Resilience
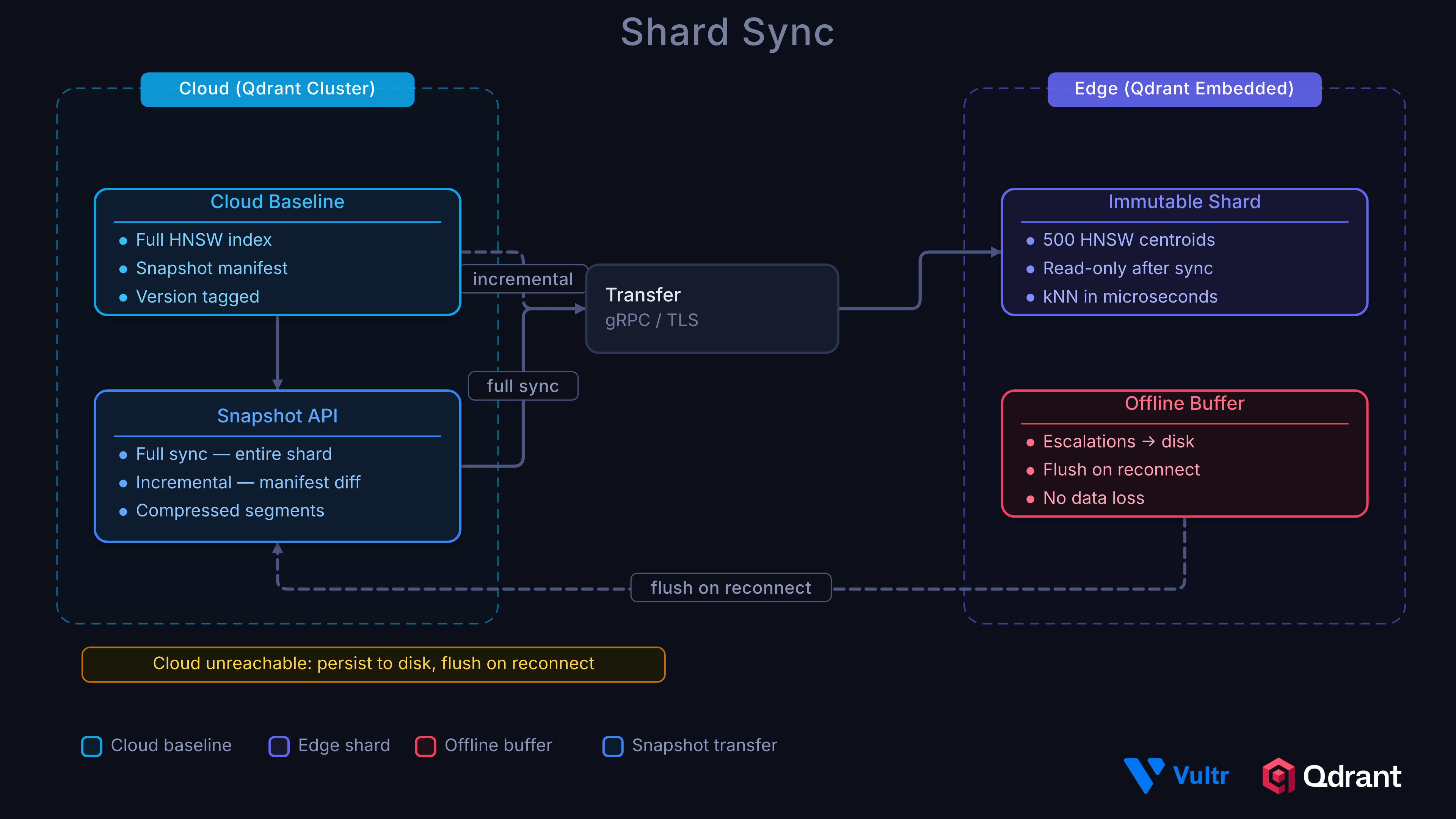
If the cloud is unreachable, escalation data is persisted to disk as JSON files:
async def escalate_to_cloud(self, clip_path, edge_embedding, edge_score, timestamp_ms=0, scene_id=""):
payload = {"edge_score": edge_score, "embedding": edge_embedding.tolist()}
try:
async with httpx.AsyncClient(timeout=30.0) as client:
data = {
"edge_device_id": EDGE_DEVICE_ID,
"edge_score": str(edge_score),
"edge_embedding": json.dumps(edge_embedding.tolist()),
"timestamp_ms": str(timestamp_ms),
"scene_id": scene_id,
}
with open(clip_path, "rb") as f:
resp = await client.post(
f"{CLOUD_API_URL}/api/escalate",
data=data,
files={"file": (Path(clip_path).name, f, "video/mp4")},
)
resp.raise_for_status()
except Exception:
# Persist to offline queue for later flush
entry = {"clip_path": clip_path, "payload": payload}
out = self._offline_dir / f"{uuid.uuid4().hex}.json"
out.write_text(json.dumps(entry))
Pending escalations are flushed during the next baseline sync cycle.
Mutable Shard Retention
The mutable shard grows with every clip the edge processes. Between syncs, all those points are searched via brute-force (no HNSW index), so query latency degrades as the shard gets larger. If the cloud is unreachable for hours, the shard grows unchecked.
The project supports three configurable retention strategies via the RETENTION_STRATEGY environment variable. Choose based on your deployment constraints.
Option A: Sync-Only Eviction (none)
RETENTION_STRATEGY=none
The default and safest option. Points are only removed from the mutable shard after a successful sync confirms they exist in the cloud. The shard grows during outages, but no data is ever lost.
Trade-off: If the camera is offline for 24 hours at 10-second clips, that’s 8,640 points in the mutable shard. On a Jetson with 8GB RAM, this is still manageable for brute-force scan, but query latency will increase.
Best for: Deployments where missing an anomaly is more costly than slower queries.
Option B: Time-Windowed Eviction (time_window)
RETENTION_STRATEGY=time_window
RETENTION_SECONDS=1800 # 30 minutes
A background worker runs every RETENTION_CHECK_INTERVAL_S seconds and deletes points older than RETENTION_SECONDS from the mutable shard. Evicted points are removed from local search but remain in the SQLite-backed upload queue for cloud sync.
def _evict_by_time(self) -> None:
cutoff = time.time() - RETENTION_SECONDS
self._mutable_shard.update(
UpdateOperation.delete_points_by_filter(
Filter(must=[FieldCondition(
key="sync_timestamp",
range=RangeFloat(lte=cutoff),
)])
)
)
Trade-off: Clips older than the retention window can’t be used for local kNN scoring. If a burst of incidents happens during an outage, the edge loses the ability to cross-reference them locally after the window expires. The cloud will still receive them via the upload queue and can re-score with higher accuracy.
Best for: Memory-constrained devices where bounded query latency matters more than local scoring completeness.
Option C: Score-Priority Eviction (score_priority)
RETENTION_STRATEGY=score_priority
RETENTION_MAX_POINTS=2000
Caps the mutable shard at RETENTION_MAX_POINTS. Unsynced points with anomaly scores above the escalation threshold are pinned and never evicted until synced. Remaining slots are filled by recency, oldest normal clips evicted first.
def _evict_by_score_priority(self) -> None:
all_points = list(self._mutable_shard.scroll(with_payload=True, with_vectors=False))
if len(all_points) <= RETENTION_MAX_POINTS:
return
pinned = []
evictable = []
for pt in all_points:
score = pt.payload.get("anomaly_score", 0.0)
synced = pt.payload.get("synced", False)
if not synced and score > ESCALATION_THRESHOLD:
pinned.append(pt)
else:
evictable.append(pt)
evictable.sort(key=lambda p: p.payload.get("sync_timestamp", 0))
keep_count = max(0, RETENTION_MAX_POINTS - len(pinned))
to_evict = evictable[:max(0, len(evictable) - keep_count)]
if to_evict:
self._mutable_shard.update(
UpdateOperation.delete_points([pt.id for pt in to_evict])
)
Trade-off: Normal clips are evicted first, which slightly reduces baseline coverage for local scoring. But the most important data (unsynced anomalies) is preserved regardless of connectivity or shard size.
Best for: Deployments where offline incidents are common and you need the edge to retain anomalous clips for local cross-referencing until connectivity returns.
Fleet Management
A real deployment has dozens of edge devices, not one. The cloud backend tracks each Jetson independently through a device registry.
Each device registers itself on first boot:
POST /api/edges/register
{
"name": "north-entrance-cam",
"location": "Building A - Zone 1",
"device_id": "edge-a1b2c3d4" # optional, auto-generated if omitted
}
From that point, escalations are tagged with edge_device_id so the cloud can track per-device performance:
POST /api/escalate
edge_device_id = "edge-a1b2c3d4"
edge_score = 0.12
edge_embedding = [...]
clip = <video file>
The registry maintains per-device stats that surface in the Sentinel dashboard:
| Metric | What it tells you |
|---|---|
escalation_rate_per_hour | How active this camera is |
confirmation_rate | How accurate its edge model is |
false_positive_rate | Whether the edge threshold needs tuning |
baseline_version | Which snapshot the device is running |
status | online, offline, or syncing |
Devices that haven’t sent an escalation or heartbeat in 5 minutes are automatically marked offline. Baseline syncs are versioned: when the cloud pushes a new snapshot to a device, its status flips to syncing until the device confirms receipt.
Per-device thresholds can be tuned independently. A camera covering a busy intersection will naturally see higher scores than one covering an empty stairwell. Rather than adjusting the global threshold, you set a device-level override:
POST /api/edges/{device_id}/sync-baseline
This triggers a snapshot download to that specific device, letting you roll out baseline updates incrementally across the fleet.
Recap
In Part 2, you built Qdrant Edge’s two-shard architecture (immutable baseline + mutable live context), implemented edge triage that reduces cloud processing by ~6x, wired the escalation pipeline with ensemble scoring and temporal boosting, and added offline resilience. The edge is running. Now we need to turn raw scores into actionable incidents.
What’s Next
In Part 3 | Scoring, Governance, and Deployment, we’ll cover incident formation from raw scores, baseline governance to prevent poisoning, unified retrieval across cameras, evaluation results on UCF-Crime, and deployment on Vultr Cloud GPUs.
Additional Resources:
- Project Repository: qdrant/video-anomaly-edge
- Part 1: Architecture, Twelve Labs, and NVIDIA VSS
- Part 3: Scoring, Governance, and Deployment
- Qdrant Edge Documentation: qdrant.tech/documentation/edge
- Twelve Labs Documentation: docs.twelvelabs.io
- Vultr Cloud GPUs: vultr.com/products/cloud-gpu